CausalMM: A Causal Inference Framework that Applies Structural Causal Modeling to Multimodal Large Language Models (MLLMs)
Recent advancements in MLLMs have led to the development of complex models like VITA and Cambrian-1, that can process multiple modalities and achieve state-of-the-art performance. Research has also focused on training-free reasoning stage improvements, such as VCD and OPERA, which use human experience to enhance model performance without additional training. Efforts to address modality priors have included methods to overcome language priors by integrating visual modules and developing benchmarks like VLind-Bench to measure language priors in MLLMs. Visual priors have been tackled by augmenting off-the-shelf LLMs to support multimodal inputs and outputs through cost-effective training strategies.
Researchers from The Hong Kong University of Science and Technology (Guangzhou), The Hong Kong University of Science and Technology, Nanyang Technological University, and Tsinghua University have proposed CAUSALMM, a causal reasoning framework designed to address the challenges posed by modality priors in MLLMs. This approach builds a structural causal model for MLLMs and uses intervention and counterfactual reasoning methods under the backdoor adjustment paradigm. This helps the proposed method to better capture the causal impact of effective attention on MLLM output, even in the presence of confounding factors such as modality priors. It also ensures that model outputs align more closely with multimodal inputs and mitigate the negative effects of modal priors on performance.
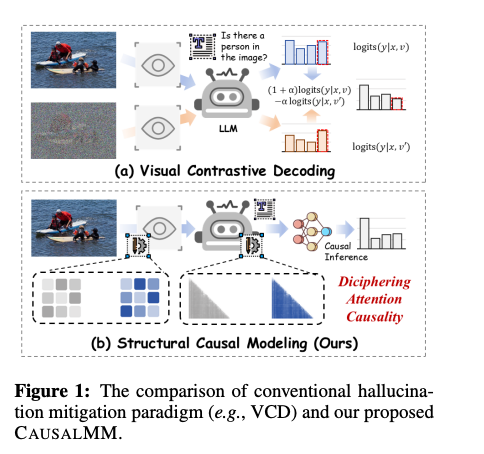
CAUSALMM’s effectiveness is evaluated using benchmarks VLind-Bench, POPE, and MME. The framework is tested against baseline MLLMs like LLaVa-1.5 and Qwen2-VL, as well as training-free techniques such as Visual Contrastive Decoding (VCD) and Over-trust Penalty and Retrospection-Allocation (OPERA). VCD mitigates object hallucinations, whereas OPERA introduces a penalty term during beam search and incorporates a rollback strategy for token selection. Moreover, the evaluation includes ablation studies for different categories of counterfactual attention and the number of intervention layers, providing a detailed analysis of CAUSALMM’s performance across various scenarios and configurations.
Experimental results across multiple benchmarks show CAUSALMM’s effectiveness in balancing modality priors and mitigating hallucinations. On VLind-Bench, it achieves significant performance improvements for both LLaVA1.5 and Qwen2-VL models, effectively balancing visual and language priors. In POPE benchmark tests, CAUSALMM outperformed existing baselines in mitigating object-level hallucinations across random, popular, and adversarial settings, with an average metric improvement of 5.37%. The MME benchmark results showed that the proposed method significantly enhanced the performance of LLaVA-1.5 and Qwen2-VL models, particularly in handling complex queries like counting.
In conclusion, researchers introduced CAUSALMM to address the challenges faced by modality priors in MLLMs. By treating modality priors as confounding factors and applying structural causal modeling, CAUSALMM effectively mitigates biases from visual and language priors. The framework’s use of backdoor adjustment and counterfactual reasoning at visual and language attention levels demonstrated reductions in language prior bias across various benchmarks. This innovative approach not only improves the alignment of multimodal inputs but also sets the foundation for more reliable multimodal intelligence, marking a promising path for future research and development in the MLLMs field.