F5-TTS: A Fully Non-Autoregressive Text-to-Speech System based on Flow Matching with Diffusion Transformer (DiT)
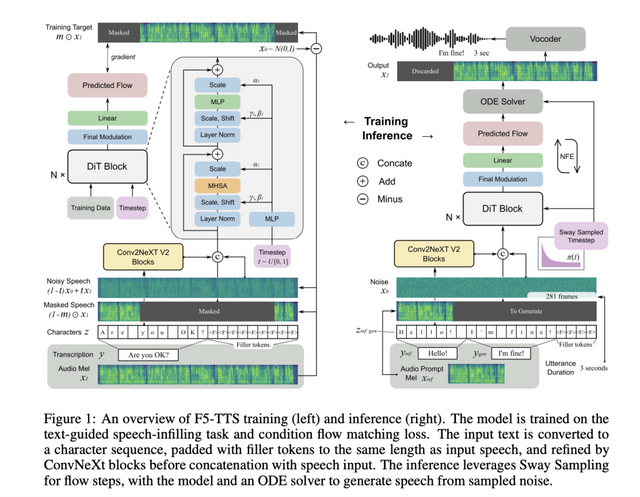
Researchers from Shanghai Jiao Tong University, the University of Cambridge, and Geely Automobile Research Institute introduced F5-TTS, a non-autoregressive text-to-speech (TTS) system that utilizes flow matching with a Diffusion Transformer (DiT). Unlike many conventional TTS models, F5-TTS does not require complex elements like duration modeling, phoneme alignment, or a dedicated text encoder. Instead, it introduces a simplified approach where text inputs are padded to match the length of the speech input, leveraging flow matching for effective synthesis. F5-TTS is designed to address the shortcomings of its predecessor, E2 TTS, which faced slow convergence and alignment issues between speech and text. Notable improvements include a ConvNeXt architecture to refine text representation and a novel Sway Sampling strategy during inference, significantly enhancing performance without retraining.
Structurally, F5-TTS leverages ConvNeXt and DiT to overcome alignment challenges between the text and generated speech. The input text is first processed by ConvNeXt blocks to prepare it for in-context learning with speech, allowing smoother alignment. The character sequence, padded with filler tokens, is fed into the model alongside a noisy version of the input speech. The Diffusion Transformer (DiT) backbone is used for training, employing flow matching to map a simple initial distribution to the data distribution effectively. Additionally, F5-TTS includes an innovative inference-time Sway Sampling technique that helps control flow steps, prioritizing early-stage inference to improve the alignment of generated speech with the input text.
The results presented in the paper demonstrate that F5-TTS outperforms other state-of-the-art TTS systems in terms of synthesis quality and inference speed. The model achieved a word error rate (WER) of 2.42 on the LibriSpeech-PC dataset using 32 function evaluations (NFE) and demonstrated a real-time factor (RTF) of 0.15 for inference. This performance is a significant improvement over diffusion-based models like E2 TTS, which required a longer convergence time and had difficulties with maintaining robustness across different input scenarios. The Sway Sampling strategy notably enhances naturalness and intelligibility, allowing the model to achieve smooth and expressive zero-shot generation. Evaluation metrics such as WER and speaker similarity scores confirm the competitive quality of the generated speech.
In conclusion, F5-TTS successfully introduces a simpler, highly efficient pipeline for TTS synthesis by eliminating the need for duration predictors, phoneme alignments, and explicit text encoders. The use of ConvNeXt for text processing and Sway Sampling for optimized flow control collectively improves alignment robustness, training efficiency, and speech quality. By maintaining a lightweight architecture and providing an open-source framework, F5-TTS aims to advance community-driven development in text-to-speech technologies. The researchers also highlight the ethical considerations for the potential misuse of such models, emphasizing the need for watermarking and detection systems to prevent fraudulent use.