Researchers from UCSD and Adobe Introduce Presto!: An AI Approach to Inference Acceleration for Score-based Diffusion Transformers via Reducing both Sampling Steps and Cost Per Step
Existing attempts to address the challenges in Text-to-Audio (TTA) and Text-to-Music (TTM) generation have primarily focused on autoregressive (AR) techniques and diffusion models. Diffusion-based methods have shown promising results in full-text control, precise musical attribute control, structured long-form generation, etc. However, their slow inference speed remains a significant drawback for interactive applications. Step distillation techniques have been explored to accelerate diffusion inference, which aims to reduce the number of sampling steps. Moreover, offline adversarial distillation methods, like Diffusion2GAN, LADD, and DMD focus on generating high-quality samples with fewer steps. However, these techniques show less success when applied to longer or higher-quality audio generation in TTA/TTM models.
Researchers from UC – San Diego and Adobe Research have proposed Presto!, an innovative approach to accelerate inference in score-based diffusion transformers for TTM generation. Presto! addresses the challenge of long inference times by reducing sampling steps and cost per step. The method introduces a novel score-based distribution matching distillation (DMD) technique for the EDM family of diffusion models, marking the first GAN-based distillation method for TTM. Moreover, the researchers have developed an improved layer distillation method that enhances learning by better preserving hidden state variance. Presto! achieves a dual-faceted approach to accelerating TTM generation by combining these step and layer distillation methods.
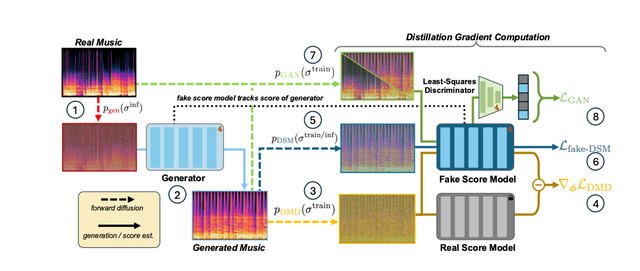
Presto! utilizes a latent diffusion model with a fully convolutional VAE to generate mono 44.1kHz audio, which is then converted to stereo using MusicHiFi. The model is built on DiT-XL and uses three conditioning signals: noise level, text prompts, and beats per minute. The model is trained on a 3.6K hour dataset of mono 44.1 kHz licensed instrumental music, with pitch-shifting and time-stretching techniques used for augmentation. The Song Describer dataset is used for evaluation, which is split into 32-second chunks and the performance is evaluated using various metrics like Frechet Audio Distance (FAD), Maximum Mean Discrepancy (MMD), and Contrastive Language-Audio Pretraining (CLAP) score. These metrics measure audio quality, realness, and prompt adherence, respectively.
Presto! has two versions Presto-S and Presto-L. The results show that Presto-L has superior performance when compared to the baseline diffusion model and ASE, utilizing the 2nd-order DPM++ sampler with CFG++. The method yields improvements across all metrics, accelerating the process by approximately 27% while enhancing quality and text relevance. Presto-S outperforms other step distillation methods, achieving close to base model quality with a 15 times speedup in real-time factor. The combined Presto-LS further improves performance, particularly in MMD, outperforming the base model with additional speedups. Further, Presto-LS achieves latencies of 230ms and 435ms for 32-second mono and stereo 44.1kHz audio which is 15 times faster than Stable Audio Open (SAO).
In this paper, researchers introduced a method named Presto! to accelerate inference in score-based diffusion transformers for TTM generation. The approach combines step reduction and cost-per-step optimization through innovative distillation techniques. The researchers have successfully integrated techniques like score-based DMD, the first GAN-based distillation method for TTM, and a novel layer distillation method to create the first combined layer-step distillation approach. The researchers hope their work will inspire future research to merge step and layer distillation methods and develop new distillation techniques for continuous-time score models across different media modalities.