Trending tags NLP Analysis: choosing a more general or a more specific tag to generate impact
Having access to the list of trending tags, a Natural Language Processing analysis could be useful in determining the impact of selecting a tag. The comparison can be made when deciding to choose one tag over the other in case of a more specific or more general tag, or selectin the singular of plural form of a tag. Grouping the tags by logical patterns leads to a new ordering of the relevance of the tags. The relevance will be defined related to number of posts, number of comments and payout.
The analysis was conducted in Python employing the wordnet library for the linguistic analysis.
Details
The data was collected from the Steemit page from the Tags section on Thursday, February 8, 2018 at around 10 am CET. The scraped data (the tags and associated counts and measurements: posts, comments, payouts) was imported and processed using Python while for the NLP processing the wordnet library for Python was employed. There was no reason in particular for selecting the data on this time or day, but the need of accessing real data for performing the analysis and drawing the conclusions.
A. Dictionary-based Analysis
There are 250 trending tags which were analyzed from a linguistic perspective. For each tag, the existence of the tag in the dictionary was determined for determining whether the tag is a common word or expression or extra knowledge about the platform is required to be able to tag the posts. 103 tags could not have been detected as common words by the dictionary, for the following reasons:
- Artificially grouped words
This category contains tags composed from two or more words with the goal of defining more clearly the category to include the post in.
portraitphotography, minnowsupport, dlivebroadcast-game, colorchallenge, introduceyourself - Abbreviations
The words included in this category are abbreviated words related to countries or specific categories.
btc, cn, nsfw, tr - Steemit platform dependent words and cryptocurrency dependent words
This category contains words and expressions that were introduced in the language with the emergence of the steemit platform.
dlive, dtube, crypto, sndbox, steem, upvote
To observe the impact of having more general categories than specific categories, I grouped the tags with artificially grouped words into more general categories: 'challenge', 'photography', 'introduce', 'steemit', 'steem', 'coin', 'crypto', 'dlive', 'dsound', kr. Then I reported the impact considering the three relevance measures proposed: number of posts, number of comments, and payouts. While the trending tags consist of a list of 250 tags, the analysis resumes to the top 10 tags for each measurement.
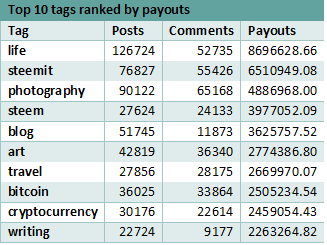
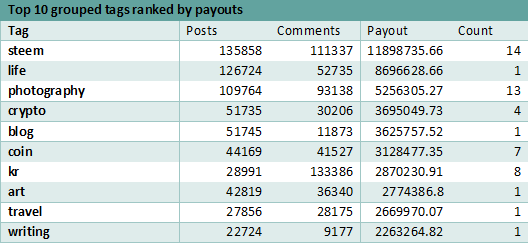
Analyzing the ranking of tags considering the most payouts, it can be noticed that while the ranking shows some changes, the tags do not change very much. The top 2 tags are the same but their order is inverted. While life tag has the most payouts in the original ranking, when grouping the tags, it is superseded by steemit. In the initial ranking, steemit is found on the second place, but when grouping the tags into more general categories, it comes up first as it now aggregates the payouts of 14 tags.
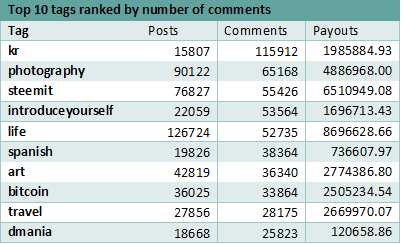
When it comes to the most commented tags, the first tag remains, in both cases (with and without grouping the tags by more general categories) and is the kr. The tags photography and steemit switch positions, while dmania (position 10 in top 10 general rankings) is replaced by crypto (in top 10 grouped tags rankings).
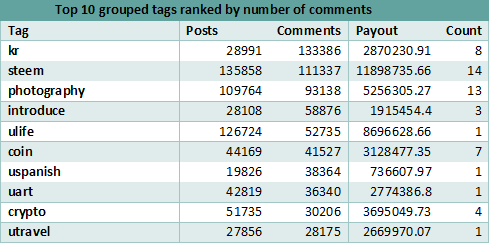
While the number of posts is not exactly a measurement of impact but the interest of people in the specific subject, they help increase the overall payout.
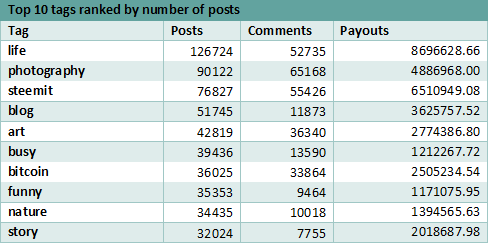
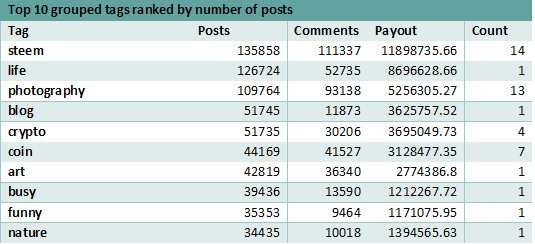
Considering all measurements, life is the tag that outperforms an overall analysis. While the other tags benefit from the more general category grouping, the life tag cannot be grouped with other categories, and remains the most popular tag on the platform.
Ranking the tags based on the number of more specific tags, shows that the steem category is the most divided, consisting of 14 different tags while photography closely follows with 13 different tags.
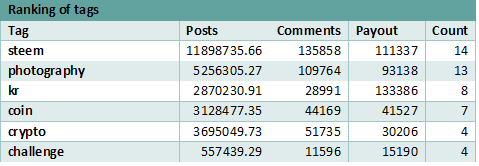
B. Part of Speech Analysis
Analyzing the tags from a grammatical perspective, it can be observed that the most tags are nouns, followed by adjectives and verbs. There were 103 tags that could not have been assigned a part of speech due to the reasons presented above. The graph shows the distribution of part of speech considering how many posts and comments were written in the pos category, while on the secondary axis are counted the number of tags for each pos.
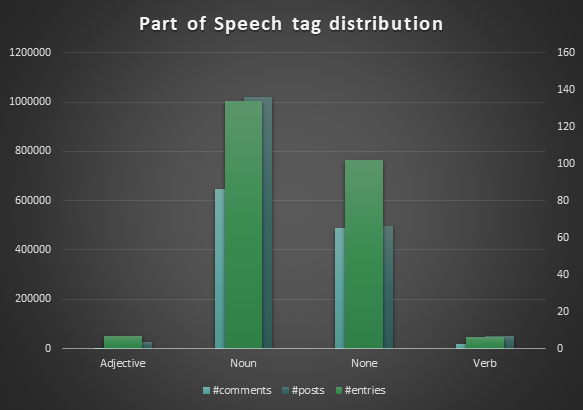
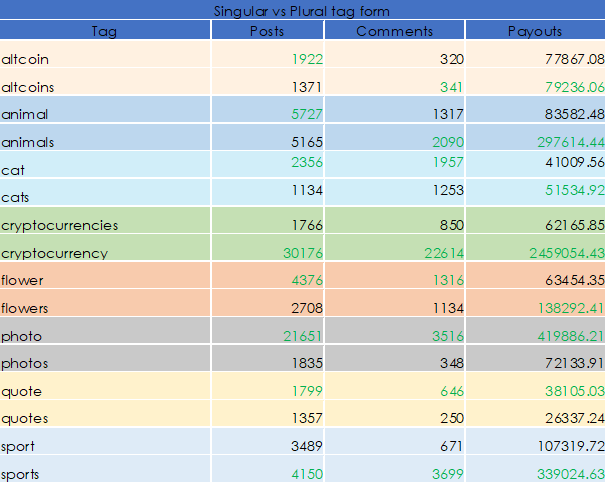
C. Plural vs Singular Analysis
There are also cases when a tag is found in the singular and the plural form. When it comes to the number of posts publishes, the most used tag is in singular form (7 tags out of 8). When it comes to the most commented posts, the most tags used are in singular form (7 tags out of 8). The most payouts were delegated to posts with plural form (5 out of 8 tags). While I find that the payouts is actually a tight score, considering the tag sports can be also considered a singular noun. So, the next time you find yourself selecting between a tag which can be either singular or plural, be sure to select plural when you want higher payout and receive more comments.
Conclusions
The current analysis shows that splitting a category into more specific categories allows for a better classification of the posts, but does not actually influence the ranking of the posts. The life tag being the most popular tag, it supersedes all other categories no matter how many subcategories they may have. Selecting between a singular or plural form for a tag can also be challenging, but the analysis shows that using a plural form may generate more impact and payouts.
Posted on Utopian.io - Rewarding Open Source Contributors
Interesting analysis of using NLP on the subject. The thing that caught my attention was 'NLP' - I thought it was Neuro Linguistic Programming. Lol
Hi @idril, this is an interesting approach! Could you please add some more information about how you gathered the data (steemsql? core query / time range / ...). I'll approve your contribution right after.
Thank you @crokkon for the reply :). Here is some additional information about the data collection process. The data was collected from the Steemit page from the Tags section on Thursday, February 8, 2018 at around 10 am CET. The scraped data (the tags and associated counts and measurements: posts, comments, payouts) was imported and processed using Python while for the NLP processing the wordnet library for Python was employed. There was no reason in particular for selecting the data on this time or day, but the need of accessing real data for performing the analysis and drawing the conclusions.
Thanks, could you just add this information to the post above?
I updated the post where I included in the Details section the data collection details. Thanks for the support :) !
Thank you for the contribution. It has been approved.
You can contact us on Discord.
[utopian-moderator]
Hey @idril I am @utopian-io. I have just upvoted you!
Achievements
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x