[Witness] Update - March 2026 | steemd
Mein letzter Post ist 5 Monate her... In der Zwischenzeit ist viel passiert. Allerdings bekommt ihr vielleicht auch nicht viel davon mit, da vieles eben im Hintergrund passiert und ich nicht wegen jeder Kleinigkeit einen Post absetze. Ich möchte euch insofern mitnehmen in die aktuellen Entwicklungen... und ich schreibe heute nur auf Deutsch.
Proposal 98
Ich hatte in meinem letzten Post schon darauf hingewiesen, dass die Grundlage der Blockchain-Umgebung aktualisiert wird (wobei es jetzt schon abgeschlossen ist). Betroffen sind unter anderem folgende wesentliche Bibliotheken:
- Rocksdb (Datenbanksystem, mit dem die Blockchain-Daten in einem Knoten gespeichert werden)
- Boost (sehr umfangreiche Bibliothek, die vom
steemd-Code genutzt wird).
Ich hatte in den letzten Wochen hauptsächlich damit zu tun, nach Fertigstellung und vor dem Einfügen den Code zu testen und herauszufinden, ob die Blockchain die Daten unverändert speichert und abruft.
Replay
Ich kann euch gar nicht sagen, wie oft ich in den letzten Wochen einen Replay der gesamten Blockchain durchgeführt habe. Es waren unzählige Male. Und jedes Mal tat sich ein neues Problem ... und später eine neue Erkenntnis auf. (Replay heißt übrigens, dass die gesamte Blockchain-Datenbank aus einem vorhandenen block_log neu angelegt wird. block_log ist eine Datei, in der alle Blöcke gespeichert sind.)
Zunächst brauchte ich für Tests eine kleinere Version der Blockchain. Also musste ich erstmal herausfinden, wie die Daten im block_log gespeichert sind. Ich möchte mir auf meinem lolalen System schließlich nicht mehrere 300GB Files ablegen. Mittlerweile kann ich jede gewünschte Größe erzeugen. So hatte ich einen block_log mit den ersten 100, 1000 und 1 Mio. Blöcken usw. So konnte ich auch lokal und mittels Debugging das Verhalten des Blockchain-Codes untersuchen.
Nach unzähligen Rückschlägen (diverse Server fielen plötzlich aus, RAM wurde knapp - dazu später mehr, die Datenbank wurde nicht richtig auf die Platte geschrieben, etc.) habe ich vor einigen Tagen dann wirklich einen definierten Stand bei 99 Mio. Blöcken sowohl in der bisherigen Version als auch in der neuen Code-Version erhalten.
Definierter Datenbankzustand
So ein Datenbankvergleich macht natürlich nur dann Sinn, wenn man Datenbanken vergleicht, die auf demselben Stand sind. Es nützt ja nun wenig, wenn in der einen Datenbank 1000 Blöcke gespeichert sind und in der anderen nur 999. Dann sind die Daten zwangsläufig verschieden.
Hier musste also ein definierter Zustand her, der Replay musste also bei einem bestimmten Block enden. Das allein ist kein Problem. Hierfür gibt es eine Start-Option. Allerdings beendet sich steemd bei Erreichen dieses End-Blockes. Wenn wir aber API-Anfragen an diesen Knoten senden wollen, um Daten abzufragen, muss steemd aber aktiv sein. Hier habe ich schon sehr früh eine Option eingebaut, mit der man den Knoten sozusagen "schlafen" legen kann. Er bekommt dann keine neuen Blöcke mehr aus dem Netzwerk und lauscht aber auf API-Anfragen.
Datenbank-Vergleich
Während ich also versuchte, einen definierten Zustand zu bekommen, haben der Chiller und ich darüber nachgedacht, wie man die Daten in der Datenbank vergleichen könnte. Auch das hielt einige Überraschungen bereit. Wundert es euch, wenn ich erzähle, dass die KI das total easy fand und auch gleich einen passenden Python-Code bei der Hand hatte? Wundert es euch auch, wenn ich erzähle, dass dieser ... und die zahlreichen anderen Codes nicht funktionierte? Was habe ich da ausprobiert. Das geht deshalb nicht (so einfach) von außerhalb, weil man die internen "Ablageregeln" (einfach ausgedrückt) kennen muss. Dies sind aber so komplex konstruiert, dass man die nicht so einfach und auf die Schnelle "nachbauen" kann. Das hat die KI einfach mal ignoriert oder andere unbrauchbare Vorschläge gemacht. Irgendwann kam der natürlichen Intelligenz (mir) die Idee, dass ich die "Regeln" dann "einfach" aus dem bestehenden System heraus nutzen kann. So entstand dann die Idee des nunmehr für den Vergleich genutzten Tools.
Rückschläge beim Vergleich
Für den Account-History-Vergleich hatte ich ein bereits vorhandenes Tool verwendet, dass API-Anfragen an beide Knoten richtet und die Ergebnisse dann vergleicht.
Schon bei dem Vergleich von 10 Mio. Blöcken sind die Knoten jedoch mehrfach vom System beendet worden. Die Abfragen haben den RAM derart beansprucht, dass das System irgendwann diese Prozesse beendete.
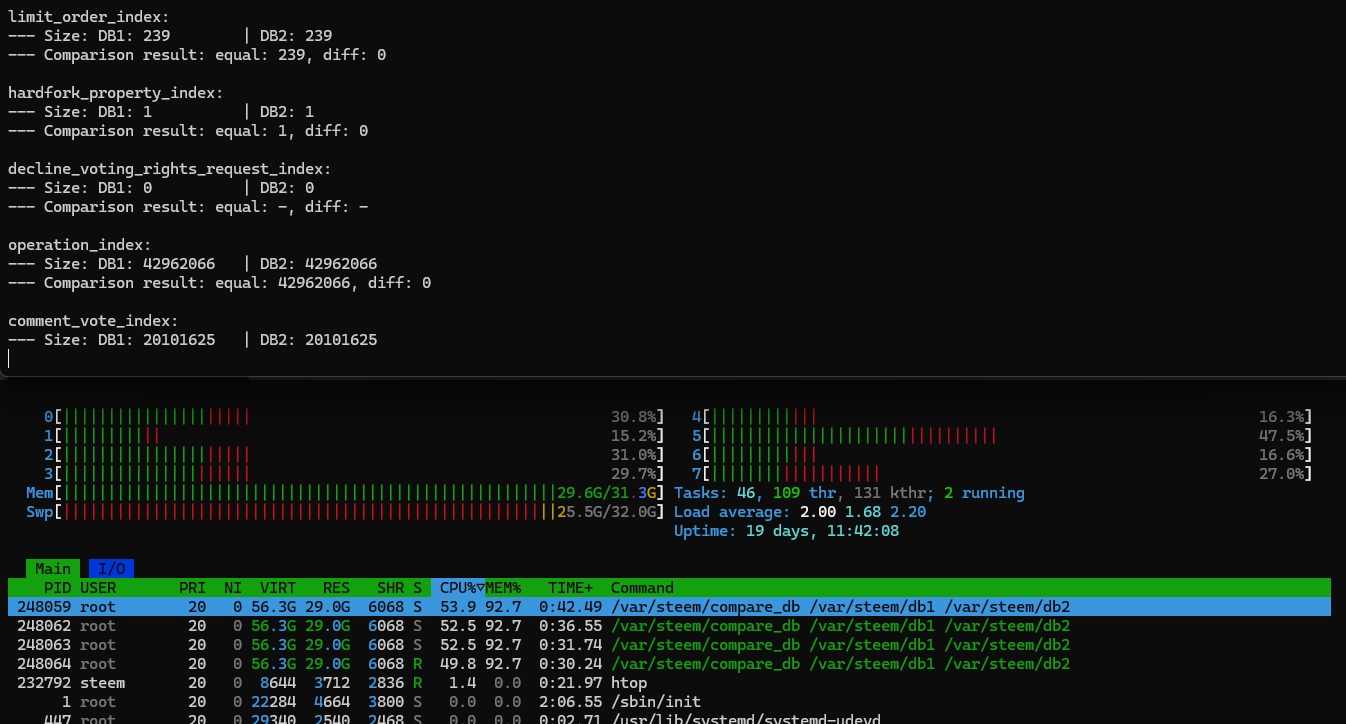
Hier sieht man beim Speicher (Mem und Swp) die vollen Balken.
Bis ich den Grund gefunden hatte, vergingen einige Stunden beim Debuggen und Testen. Es war der
steemd-interne Cache, der alle Abfragen zwischenspeichert. Das ist nun mal die Aufgabe eines Caches, aber leider sieht der aktuelle Code keine Bereinigung vor... jedenfalls dann nicht, wenn keine neuen Blöcke reinkommen. (Zur Erinnerung: das hatte ich deaktiviert, da ich ja einen definierten Zustand brauchte.)Als ich dann in mein Tool noch die Cache-Bereinigung eingebaut hatte, funktionierte nun endlich alles reibungslos.
Finaler Erfolg
Tja, irgendwann vor ein paar Tagen hatte ich dann endlich den Container mit dem Vergleichs-Tool gestartet, und dieser hat ohne zu murren die Datenbanken-Einträge der beiden steemd-Versionen verglichen... Mit Erfolg (hier ein Auszug aus dem log):
Timing enabled for comparisons
Memory usage reporting enabled
Running in serial mode (no multithreading)
-------------------------------------------------------
Open database from /var/steem/db1
884335ms block_log.cpp:142 open ] Log is nonempty
884340ms block_log.cpp:151 open ] Index is nonempty
Revision: 99000000, Head Block: 99000000
-------------------------------------------------------
Open database from /var/steem/db2
893140ms block_log.cpp:142 open ] Log is nonempty
893140ms block_log.cpp:151 open ] Index is nonempty
Revision: 99000000, Head Block: 99000000
-------------------------------------------------------
account_index:
--- Size: DB1: 1940572 | DB2: 1940572
--- Progress finished (1940572/1940572)
--- Elapsed time: 64.286s
--- DB1 memory: Index cache usage: 46282771, Index cache size: 100000
--- DB2 memory: Index cache usage: 46282771, Index cache size: 100000
--- Comparison result: equal: 1940572, diff: 0
--- DB1 memory: Cache usage: 46282771, Cache size: 100000
--- DB2 memory: Cache usage: 46282771, Cache size: 100000
comment_vote_index:
--- Size: DB1: 916346408 | DB2: 916346408
--- Progress finished (916346408/916346408)
--- Elapsed time: 6459.21s
--- DB1 memory: Index cache usage: 4700000, Index cache size: 100000
--- DB2 memory: Index cache usage: 4700000, Index cache size: 100000
--- Comparison result: equal: 916346408, diff: 0
--- DB1 memory: Cache usage: 4700000, Cache size: 100000
--- DB2 memory: Cache usage: 4700000, Cache size: 100000
... und nun?
Ich denke, wir können die Änderungen, die bisher nur im Entwicklungs-Stadium waren, nunmehr in den Production-Code übernehmen. Alle Top-Zeugen sollten dies entsprechend checken und ihre Meinung dazu äußern. Und darauf können wir dann die weitere Entwicklung der Steem-Blockchain aufbauen...

Steem Search on https://moecki.online/ |  |
|---|
28.03.2026
NI rulez!
Du veröffentlichst hiermit ein Kapitel aus dem Buch mit sieben (naja, vielleicht fünf) Siegeln und ich bin dir sehr dankbar, dass du dir so viel Mühe gegeben hast, etwas vom Fachchinesisch abzurücken. Besonders gefällt mir der schlafende Knoten - da kann der Laie sich doch echt mal etwas drunter vorstellen... 😇
Ansonsten hört sich das Ganze nach ziemlich viel Arbeit, noch mehr Ehrgeiz und am Ende einem großen Erfolg an!
Muss ich mir das ein bisschen (also in der Miniaturvariante) so vorstellen, wie damals, als ich immer wieder den Rechner neu aufsetzte, weil er immer wieder an der selben Stelle hängen blieb, ich aber unbedingt herausfinden musste, weshalb. Man mich ob der Ausdauer schon für bescheuert erklärte, das Glücksgefühl nach gefundener Lösung dann aber sämtlichen Zeitaufwand und Spott überwog?! Zum Glück gab es damals keine Allwissenden Intelligenzbestien, die einem Unfug erzählten, man aber glaubte, sich hundertprozentig drauf verlassen zu können. Ein Hinweis guter Freunde, noch mal das ein oder andere genauer unter die Lupe zu nehmen, war aber stets willkommen... ☺️
Wie kann man denn nun sicher stellen, dass alle Zeugen die selben "Blockpartitionen" miteinander abgleichen?
Oder stellt sich die Frage gar nicht?
Ach, ich fürchte, ich werde die Antwort eh nicht verstehen... 😉
Hut ab!
Danke!
Ist mir also doch ein wenig gelungen :-) Meine Haupt-Zielgruppe waren diesmal die weniger technisch versierten deutschen User, die für mich als Zeugen voten.
Ja, man könnte dies so vergleichen :-)
Ich musste tatsächlich immer wieder von vorn beginnen... und ja, ich wollte unbedingt wissen, warum das oftmals schief ging. Blöd war halt nur, dass vom Start bis zu dem Punkt, an dem es spannend wurde, teilweise mehr als 10 Tage vergingen. Da kommt man nicht so wirklich vorwärts...
Nö :-D
Das habe ich sozusagen stellvertretend für alle gemacht. Wäre natürlich schön, wenn das noch jemand nachvollzogen hätte, aber offensichtlich hatte dazu keiner Zeit/Lust.
Wenn der Code in den offiziellen Code eingefügt wird, müssen alle Zeugen nur ihre Knoten auf den neuen Code umstellen. Da es sich um eine Softfork (und eigentlich nicht mal das) handelt, müssten die Zeugen nicht mal zwingend den neuen Code verwenden, um weiterhin Blöcke zu validieren.
Hihi - ick wollte mir schon janz schlecht und dummlich vorkommen, weil ick nix verstehe... Danke für die Egalisierung ;-)))
Auch für solche Fälle gibt es einen Gruß von !dubby 20%.
Oh oh, das war wohl ein Ritt! Zum Glück gibt's noch NI (natürliche Intelligenz) die sich zu helfen weiß ;-)
Das üble bei KI, wenn die sich mal verlaufen hat, bringt man sie nicht mehr so leicht vom Holzweg runter. Wie ein Navi, der dich ständig auf die gesperrte Strecke leiten will.
Größten Respekt für deinen Einsatz und Gratulation an alle die "Comparison result: equal" möglich gemacht haben!
Ach ja, bei deiner Suche kommt "403 Forbidden" - da hat's wohl etwas verbogen oder ist das nur bei mir so?
Da sagst du was! Wenn ich es wage, eigenständig ihrer Vorschläge abzuändern.... da will sie das beim nächsten Mal direkt wieder rückgängig machen. Das ist auch so etwas, was mehr Arbeit macht. Ich muss dann erstmal aufwändig durchschauen, was geändert werden soll.
Vielleicht liegt es aber auch an mir. Möglicherweise muss ich meine Fähigkeiten im Umgang mit ihr auch erst noch ausbauen...
Hm, das Problem habe ich nicht. Meinst du direkt beim Aufruf von https://moecki.online ?
Ja, das kommt bei mir am Handy und PC (Vivaldi-Browser und Firefox, auch im privat Modus)
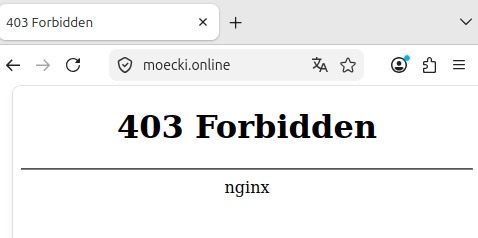
Mal @chriddi fragen, ob sie auf https://moecki.online kommt :-)
Hm, seltsam...
Was sagt denn deine Konsole/Netzwerkanalyse im Browser?
Hallo @moecki,
vielen Dank, dass du unseren automatischen Auszahlungsbot DUBby nutzt, um deine Kommentatoren anteilig an deinen Post-Rewards zu beteiligen.
Du hast bisher noch keine Auszahlungsbefehle erteilt.
Schreibe dafür einfach einen Kommentar an die User, die einen Anteil erhalten sollen. Darin sollte die Anweisung in der Form
!dubby x %enthalten sein.Falls du dazu Hilfe benötigst, kannst du gern fragen oder in diese Anleitung schauen.
Gruß vom DU-Finanzbot (by Witness @moecki).
Konsole gibt nicht viel her:
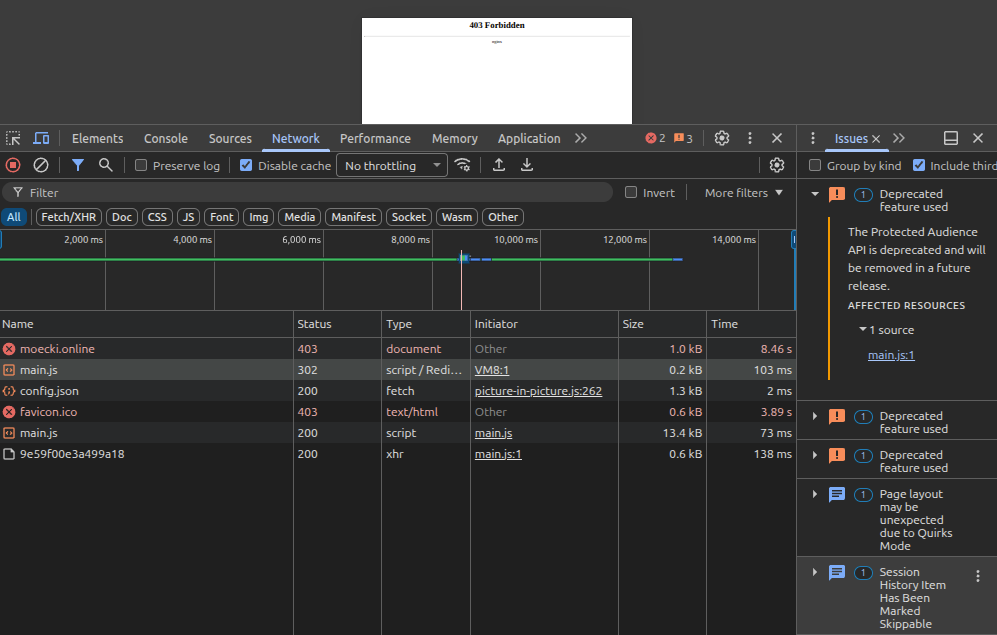
Ich probier es nächste Woche von einem anderen Standort. Wenn es bei Chriddi und dir funzt, liegt es evtl. nicht an deinem Server. Spooky... :-)
Ich glaube, ich hatte heute etwas ähnliches..
Hast du vielleicht nur die Seite aktualisiert? Oder gänzlich neu aufgerufen?
Ich hatte die Meldung (allerdings nur in ähnlicher Weise), wenn ich die Seite nur aktualisiere. Ich vermute, das hängt mit der Bot-Überprüfung zusammen.
!dubby 25%
Holla, schau mal:
Zufällig kam ich drauf, meine FritzBox hat wieder einmal selbstständig (schon vor einiger Zeit) IPV6 eingeschaltet, das mag Cloudflare (oder deine Seite?) nicht. Jetzt, nur IPV4 aktiv, komme ich wieder auf deine Seite.
Lustig oder?
Google war der zündende Tippgeber, auf einmal meldete google.de im Privatmodus aufgerufen verdächtige Netzwerkaktivitäten, ich wäre evtl. ein Bot... Na ja, vielleicht :-) Jetzt, mit IPV4 ist die Meldung verschwunden, evtl. ist meine IPV6 auf einer Blacklist gelandet, keine Ahnung.
Jedenfalls Rätsel gelöst!
Okay, das hätte ich jetzt nicht erwartet.
Ich habe weder IPv6 geblockt noch mich aktiv darum gekümmert. Kann natürlich sein, dass es an irgendeiner Stelle mit IPv6 hakt. Ich würde aber vermuten, dass Cloudflare das schon unterstützt oder unterstützten sollte.
Kann aber sein, dass ich hierfür beim Reverse Proxy noch zusätzlich konfigurieren muss... ich behalte das mal im Hinterkopf.
Wo ich so darüber nachdenke: als ich damals die vielen Anfragen hatte, waren schon auch IPv6-Adressen dabei. Zumindest was die API- und Steemit-Domain angeht...
Hmm, wie meinst du das? Ich hatte die Seite aufgerufen, Konsole/Untersuchen geht ja erst danach. Und dann natürlich die Seite aktualisiert. Wüsste nicht, wie es anders geht.
Aber mach dir kein Kopf, nächste Woche probier ich es mal extern, also nicht von zu Hause aus, dann sind wir schlauer.
Schönen Gruß an Dubby, besten Dank! Und dir und deiner Family frohes Eiersuchen.
Ich habe etwas herausgefunden:
Diese Bot-Ausschlussprüfung, die Möcki in seine Seite integriert hat, setzt bei mir eine lange, merkwürdige Zeichenfolge hinter den ursprünglichen Link.
Ich gehe davon aus, dass du die Seite so nicht als Lesezeichen gespeichert hast. Dann nämlich wird der Zugriff auf alle Fälle verweigert.
Wenn ich die Seite nach ein, zwei Tagen "refreshe" geht auch nichts, man muss schon "original" wieder rauf.
Möglicherweise behält dein Browser die Zeichenfolge im Cache?
Wow, ich sehe du verstehst mich sogar auf diesem Gebiet... :-D
Genau das meinte ich mit "Seite aktualisieren". Ich hatte das auch mal und mit der "alten" Zeichenfolge wollte er mir auch die Seite nicht ausliefern.
Oh, schön, dass du an mich gedacht hast! Ja, bei mir ist auch dieses lange Anhängsel nach der Prüfung, danach lande ich aber irgendwie in der "verbotenen Zone". Es liegt leider nicht am Cache, hatte es auch im privaten Modus und in verschiedenen Browsern probiert.
Ich hab da so einen Verdacht, den kann ich aber erst nächste Woche prüfen.
😂 ich hänge in einer Endlosschleife der Überprüfung von Cloudflare das ich ein Mensch bin, auf Chromebrowser auf Firefox geht´s seltsamerweise
Ich hoffe, du hängst da nicht immer noch ;-))
Wie Cloudflare das mit der Überprüfung macht, entzieht sich meinem Einfluss. Das ist vorgelagert, bevor überhaupt deine Anfrage an meinen Server weitergeleitet wird.
Manchmal muss man auch manuell mit Klick oder Tipp erst bestätigen, dass man ein Mensch ist...
Ups...
Jepp, mir wird der Zugang auch verwehrt.
Edit 10 Stunden später:
Passt jetzt wieder alles… 😁
Bei mir geht immer noch nix, zusätzlich hat sich noch steemit verabschiedet:

Aber wir haben ja steemit.moecki.online - das funzt 👍
Da bin ich schon beruhigt :-)
!dubby 25%
Dankeschön 😁
Du und @steemchiller seid heute für Euer Engagement auch ohne Kommentar und Upvote des Tippost für die heutige Samstagsziehung bei @lotto4you für ALLE 3 Spielvorraussagen mit einem gemeinsamen 10% Gewinnanteil mit den anderen Teilnehmern am Gesamtgewinn automatisch für heute gesetzt.
https://steemit.com/deutsch/@lotto4you/samstagslotto-tippost-fuer-die-ziehung-am-28-3-2026-love
Vielleicht haben wir Glück und Euer Engagement wird fett belohnt.
Vielen Dank
✨🍀🙏
Nun sind wir einen Versuch klüger :-)
!dubby 10%
Hi @moecki. I want to delegate you 1000 sp of mine. Can I get the same amount of votes as @maxart?
🤯
https://steemit.com/ukraine-on-steem/@maxart/tb53af
No, I cast my votes solely on the basis of the content or engagement, not because of any delegations.
Thanks to you..
turn-off