学习了一下Base58编解码
之前YY了基于STEEM区块链的聊天工具以及STEEMIT 用户地图
可惜YY不能强国,也不能健身,只有踏踏实实的做事情,才是正道啊。

Base58 简介
最近一些学啊学的,都学吐血了
然后突然又发现一个新东西,Base58
话说以前做网站啊,或者邮件啥的经常听说Base64, 这个Base58又是什么鬼
查了一下维基百科:
https://en.wikipedia.org/wiki/Base58
Base58 is a group of binary-to-text encoding schemes used to represent large integers as alphanumeric text.
粗略一看,原来就是用于把大数字表示成字符形式
那我就不懂了,直接表示成十进制或者十六进制字符就完结了呗,搞什么事情?!!
再仔细一看
Compared to Base64, the following similar-looking letters are omitted: 0 (zero), O (capital o), I (capital i) and l (lower case L) as well as the non-alphanumeric characters + (plus) and / (slash)
输入文本串的时候傻傻的分不清出0和O, I 和l 有木有?中枪的🙋
这个Base58就避免了这个问题,看来凡事出现都是有缘由的。
听说还有个变种Base56,去的更彻底,不过咱没遇到,就不研究它了
A variant, Base56, excludes 1 (one) and o (lowercase o) compared to Base 58.
然后我总结了一下,就是把数字表示成不容易输入错误的文本编码
维基百科里并没有说到,因为这组不容易出错的文本编码一共包含58个字符,所以叫Base58
Base58 编码规则
维基百科中并没有说明Base58详细编码规则
相比之下,Base64 则是亲妈养的
https://en.wikipedia.org/wiki/Base64
但是讨论维基百科是不是Base58的亲妈,貌似于事无补,所以我决定继续我的探索之路。
好在维基百科还算厚道,给出了Base58亲弟弟Base58Check_encoding的链接
https://en.bitcoin.it/wiki/Base58Check_encoding
之所以说亲弟弟,是因为长江后浪推前浪,弟弟比哥哥长得更高更壮,好吧,其实就是这个链接里的信息更多而已
比如说,多出了这么个玩意
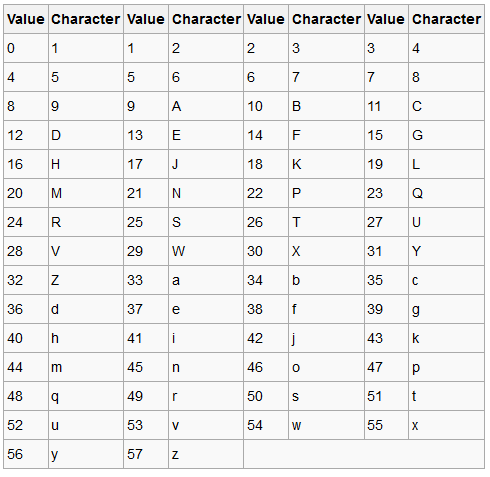
我横看,竖看,左看,右看,我脖子哎,咋也没看明白
直到我看到下边这行代码:
code_string = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
我擦,不就是查表法的一个表嘛,何必整那么复杂,再回头看看,上边也就是一个表,我晕
里边说了地址编码的算法
The algorithm for encoding address_byte_string (consisting of 1-byte_version + hash_or_other_data + 4-byte_check_code) is
code_string = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
x = convert_bytes_to_big_integer(hash_result)
output_string = ""
while(x > 0)
{
(x, remainder) = divide(x, 58)
output_string.append(code_string[remainder])
}
repeat(number_of_leading_zero_bytes_in_hash)
{
output_string.append(code_string[0]);
}
output_string.reverse();
我又想吐学了,气的我都不会打字了,这分明是把最后生成的地址编码一下嘛,整的我去找半天啥算法呢?
跟这些玩意consisting of 1-byte_version + hash_or_other_data + 4-byte_check_code有啥关系?写一大堆忽悠我。
Python 实现
实现之一:
咦,话说我咋找不到从哪里找到的这个链接了
https://github.com/keis/base58/blob/master/base58.py
steem 官方Python库中Base58 实现
https://github.com/steemit/steem-python/blob/master/steembase/base58.py
# https://github.com/tochev/python3-cryptocoins/raw/master/cryptocoins/base58.py
BASE58_ALPHABET = b"123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
def base58decode(base58_str):
base58_text = bytes(base58_str, "ascii")
n = 0
leading_zeroes_count = 0
for b in base58_text:
n = n * 58 + BASE58_ALPHABET.find(b)
if n == 0:
leading_zeroes_count += 1
res = bytearray()
while n >= 256:
div, mod = divmod(n, 256)
res.insert(0, mod)
n = div
else:
res.insert(0, n)
return hexlify(bytearray(1) * leading_zeroes_count + res).decode('ascii')
def base58encode(hexstring):
byteseq = bytes(unhexlify(bytes(hexstring, 'ascii')))
n = 0
leading_zeroes_count = 0
for c in byteseq:
n = n * 256 + c
if n == 0:
leading_zeroes_count += 1
res = bytearray()
while n >= 58:
div, mod = divmod(n, 58)
res.insert(0, BASE58_ALPHABET[mod])
n = div
else:
res.insert(0, BASE58_ALPHABET[n])
return (BASE58_ALPHABET[0:1] * leading_zeroes_count + res).decode('ascii')
是不是很简单?
神马? 不明白?
其实就是把编码后的文本数字串,转换成一个大整数,然后再按58进制表示。
什么? 58进制没听过, 16进制总听说过吧? 略有区别的是16进制字符0-15和0x0 - 0xF是一一对应的,而这个0-57,需要查表对应,仅此而已!解码就是逆过程!
(上边这两段话,是我吐血总结出来的!! )
至于Base58Check是咋check的,就先不研究了,吐学去了。
o哥,看的我头大了
+1
+1
+N
+2
Great post, thanks for sharing!
Im following you !
Resteeming this to my followers. Hope it helps a little.
yes i dont understand ur post because its in ur language post in english @oflyhigh sir thanx
The code is the only thing I understand lol
0x 以太不就这个开头的嘛
啊,😄 其实我也就对Steem 还略算熟悉
😢
大神,还是不大明白啊
我只是初学者
😢
你確定你是初學嗎!!😝
I haven't understood because of the language.
https://steemit.com/steem/@misterbitcoin/56gexk-upvote-steem-world-helping-each-other-with-your-upvote
Thanks, great information!
真是做什么的都有。我准备搞个基码,全翻译成汉字。申请个专利。谁告诉我怎么申请中国专利?