PDF A3 裁剪为 A4 小工具 V2 版 较 V1 版增加预览功能
V1版 PDF A3 to A4 裁剪工具我写了,能用。但用着用着发现一个问题:点一下就裁完了,进度条一走,文件出来了——可我压根不知道它到底认对了没。有几页我明明觉得不该裁,它也给我裁了。裁都裁完了,想反悔得重新来。
所以这次重写了一版,核心就一个改动:裁之前,先让你看清楚每一页会怎么裁。
v2 干了什么:加了个预览
老版本是「拖进去 → 点一下 → 直接出文件」。
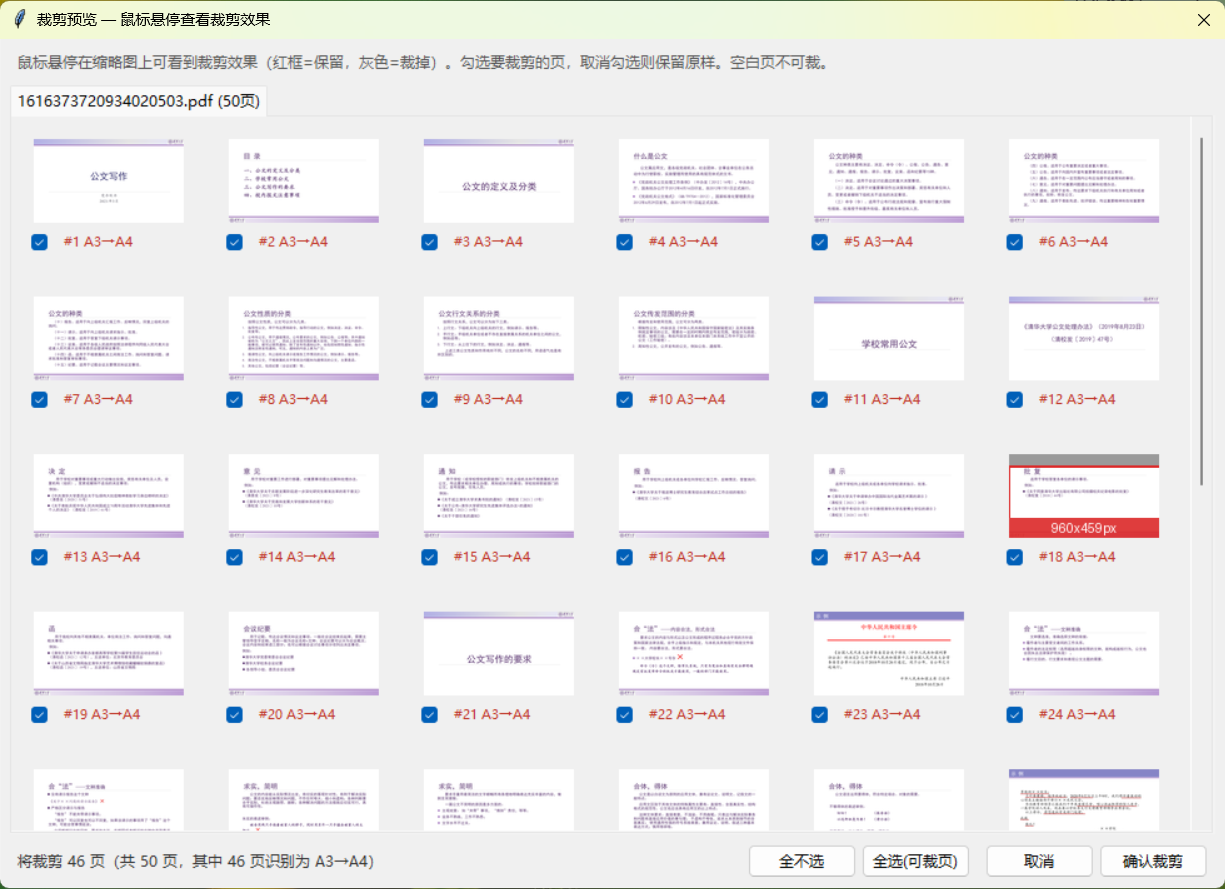
新版本变成「拖进去 → 点分析 → 弹出预览窗口 → 你确认 → 再出文件」。
多出来的这个预览窗口,干三件事:
第一,鼠标移上去就能看裁剪效果。 每一页是个小缩略图,鼠标一放上去,图上立刻出现一个红框——红框圈住的是要保留的内容,框外面那一片会变灰,表示要被裁掉。不用脑子想「它会把哪部分留给我」,眼睛一看就知道。
第二,能逐页勾选。 觉得哪页不该裁,把它前面的勾去掉就行。默认是识别成「A3 扫成 A4」的页自动打勾,你可以反悔。
第三,批量也能分开看。 一次拖十几个 PDF 进去,预览窗口上面一排标签页,每个文件一个标签,点哪个看哪个,互不干扰。
这个改动的意义在于:裁剪变成了一个可以撤销、可以审查的动作,而不是一个开盲盒的动作。 以前是赌它认得准,现在是先看它认得准不准。
裁剪的思路(这次直接讲)
后台算法没变,还是那一套,简单讲清楚:
算法是像素投影法,不是 AI。 把一页 PDF 渲染成图像,逐行逐列统计「非白色像素的比例」,找到内容块的上下左右边界。
具体说,先把灰度图二值化——像素值低于阈值(默认 245)的算「有内容」。然后算每一行里内容像素占多少比例(行投影),每一列里占多少比例(列投影)。比例超过一个最小值(千分之五)的行/列,才算「真的有内容」。把这些有内容的行取最上面和最下面,就是内容的上下边界;列同理,就是左右边界。
如果某个方向上空白的比例超过 40%,就判定这是「A4 被扫成 A3 了」。判定之后不是从中间一刀切,而是先找到内容的真实边界,再在边界外面留 2% 的余量——免得把紧贴边缘的字裁掉。
输出 PDF 的尺寸是按 DPI 反算物理尺寸的。 比如 200 DPI 下 A4 大概 1654×2339 像素,裁完内容区域后,用像素数 ÷ DPI × 25.4 算出毫米数,再生成等比例的 PDF 页面。所以裁完的文件打开看,页面尺寸基本就是 A4。
预览这一步用的是低分辨率,输出用的是高分辨率。 预览只要让你看个大概、确认边界对不对,用 72 DPI 渲染就行,几页文件一秒扫完。等你确认了要裁哪些页,再切到 200 DPI 正式裁剪输出,保证清晰度。两步分开,预览快、输出清晰。
鼠标悬停看裁剪效果是怎么做的。 分析的时候,每一页生成两张缩略图:一张是原图,一张是用 Pillow 画了红框和灰遮罩的标注图。鼠标移上去,就把那张图换成标注图;鼠标移开,换回原图。纯粹是两张图在切换,响应是即时的,没有延迟。
界面还是 tkinter 写的,Python 自带,不依赖任何第三方 UI 框架。省掉了一套 Qt 或 Electron,打包体积小了一半。
为什么不做在线版
这类工具逻辑不重。不需要显卡,不需要云算力。传文件上去唯一的受益者是服务提供方。
这个工具全是本地跑:选文件用的是系统对话框,处理用的是 PyMuPDF 和 Pillow 两个 Python 库,网线拔了照样干活。你的文件自始至终没离开你的硬盘。发票上有税号和公司抬头,往陌生服务器上传,我是真不敢。
几个细节
打包成单文件 exe,大概 50MB。首次启动要解压内置资源到临时目录,会多等两秒,之后正常运行。如果杀毒软件误报,添加信任即可。
源码 AGPL-3.0 授权,随便改。核心依赖 PyMuPDF 也是 AGPL-3.0,所以分发 exe 的时候必须一并提供源码——这也是为什么压缩包里 exe 旁边带着一个
code/文件夹。支持拖拽(装了 tkinterdnd2 的话),没装也能用按钮选文件。
macOS / Linux 直接跑
code/里的源码。
怎么拿到
下载地址:城通网盘
网盘密码:0033
解压密码:PDF空白裁剪工具 v2.0 .7z
压缩包里有:
PDF空白裁剪工具.exe,双击跑code/完整 Python 源码,pip install -r requirements.txt就能跑README.md使用说明和常见问题
macOS / Linux 直接跑 code/ 里的源码。
最后:这套东西是用什么做出来的
核心算法思路是我提的:用像素投影检测内容边界、低分辨率预览 + 高分辨率输出、鼠标悬停切两张图显示裁剪框——这些是我想清楚了让它去实现。具体到每一行代码、边界换算、tkinter 的标签页和滚动网格,是 GLM-5.2 + ZCode 0.14.8 完成的。
整个开发过程没有一个代码是我手敲的,全是描述需求 + 审查它写的 + 让它改。
如果你也想用 AI 写代码,这两个是正主:
- 👉 Z.AI — GLM 官方海外版,体验 GLM-5.2 的能力
- 👉 OpenCodeGo — 多模型订阅平台,5 美元一个月,可用60美元额度,国内主流的开源模型都能用
本软件 + 本文全部使用 AI 辅助完成。
Upvoted! Thank you for supporting witness @jswit.