Stanford Researchers Propose LoLCATS: A Cutting Edge AI Method for Efficient LLM Linearization
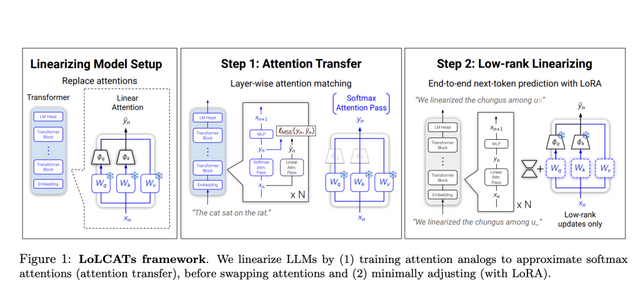
Researchers from Stanford University, Together AI, California Institute of Technology, and MIT introduced LoLCATS (Low-rank Linear Conversion via Attention Transfer). LoLCATS is a two-step method designed to efficiently improve the quality of linearized large language models without the need for expensive retraining on billions of tokens. The core idea behind LoLCATS is to first train linear attention mechanisms to match the softmax attentions of the original model using a mean squared error (MSE) loss in a process called “attention transfer.” Then, low-rank adaptation (LoRA) is employed to correct any residual errors in approximation, allowing the model to achieve high-quality predictions with significantly reduced computational costs. This method makes it feasible to create linearized versions of very large models, like Llama 3 8B and Mistral 7B, with minimal overhead.
The structure of LoLCATS involves two main stages. The first stage, attention transfer, focuses on training the linear attention to closely approximate the output of softmax attention. The researchers achieved this by parameterizing the linear attention using learnable feature maps, which are optimized to minimize the output discrepancy between the linear and softmax mechanisms. The second stage, low-rank linearizing, further improves model performance by leveraging LoRA to make small, low-rank adjustments to the linearized layers. This step compensates for the quality gaps that might emerge after the initial linearization. The LoLCATS framework also employs a block-by-block training approach, particularly for larger models, to make the process scalable and more memory-efficient.
The results presented in the research demonstrate significant improvements over prior linearization methods. For example, LoLCATS successfully closed the performance gap between linearized and original Transformer models by up to 78% on a standard benchmark (5-shot MMLU). The researchers also highlight that LoLCATS achieved these improvements while only using 0.2% of the model parameters and 0.4% of the training tokens required by previous methods. Additionally, LoLCATS is the first method that was successfully used to linearize extremely large models, such as Llama 3 70B and 405B, enabling a considerable reduction in computational cost and time compared to earlier approaches.
Conclusion
LoLCATS presents a compelling solution to the problem of linearizing large language models by significantly reducing the memory and compute requirements without compromising on quality. By introducing the two-step process of attention transfer followed by low-rank adaptation, this research enables the efficient conversion of large Transformer models into linearized versions that retain their powerful capabilities. This breakthrough could lead to more accessible and cost-effective deployment of LLMs, making them feasible for a broader range of applications. The implementation details, along with the code, are available on GitHub, allowing others to build upon and apply this method to other large-scale models.