Compelled philanthropy or the story of how AI labs pay to train their own replacements
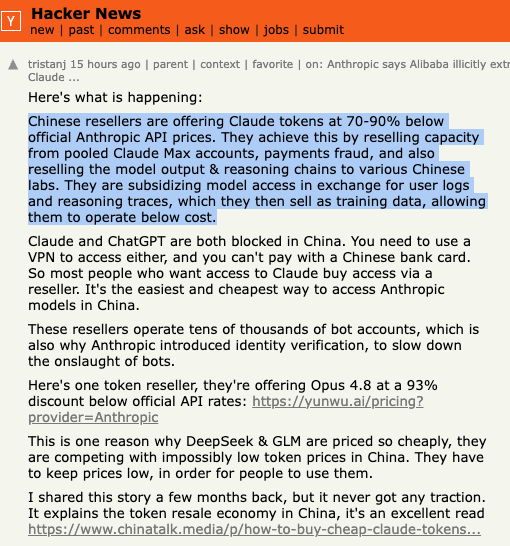
Did you catch the newest trend in AI economics? Somewhere in China, a reseller buys a single $200-a-month Claude Max subscription. Rather than use it the way one person would - a few hours of typing here, a coding session there - they pool it across a server farm, routing requests through dozens or hundreds of accounts, rotating through residential proxies so the traffic never looks like what it actually is: a single subscription divided among thousands of paying customers who could never legally buy the product themselves, since Anthropic doesn't accept Chinese bank cards and Claude is blocked in China outright, meaning even a determined individual would need a VPN, a foreign card and the patience to survive identity verification. The reseller absorbs all of that friction once, at scale, then sells the output downstream at a 70-90% discount to the official API rate. Divide a flat monthly fee by a denominator several orders of magnitude larger than the one it was priced for and the per-token economics basically solve themselves. Nobody breached a server, nobody stole a model weight - somebody just did arithmetic that Anthropic's pricing team would very much prefer nobody did out loud.
What makes this more than a curiosity is the mechanism it exposes, because it isn't unique to Anthropic or to China or even to AI. It's the same actuarial logic that underwrites gym memberships, unlimited data plans and all-you-can-eat buffets: price a flat fee against the assumption that most subscribers will underuse it and pocket the difference. That logic survives perfectly well when the underlying good is physically scarce - a treadmill can only hold one body at a time, a buffet tray only holds so much shrimp. A digital good behaves differently, since the marginal cost of serving the thousandth simultaneous user sits almost identical to the cost of serving the first. A barbell enforces its own rate limit - a token doesn't. The moment someone realizes that a $200 subscription contains, by some estimates floated in the discussion, upward of $2,000-3,000 worth of metered API value if used continuously, the entire pricing tier stops looking like a consumer product and starts looking like a wholesale commodity waiting for an arbitrageur to discover it and discover it they have, with the same instinct that turned Costco memberships into informal day-pass rental businesses and Sam's Club gas into a side hustle for people willing to sit in a parking lot.
The situation gets more interesting once you look at what the resellers are reportedly doing with what they're skimming. It goes beyond simple resale. The same middlemen undercutting Anthropic's published pricing are allegedly logging every prompt and every completion their subsidized users generate and, in some accounts, every visible token of reasoning trace, then selling that corpus to Chinese AI labs hungry for distillation data. If that holds up, the economics invert in a genuinely strange way: Anthropic ends up not merely losing margin on resold tokens, but effectively subsidizing the compute that manufactures the training data eroding its own model's distinctiveness. Picture a software company discovering that its free-trial users weren't simply underpaying, but were being paid by a rival to generate usage logs the rival then trained on. Nothing here was extracted that wasn't first willingly served, which makes "theft" a strange word for it. "Compelled philanthropy" fits better, where the victim foots the bill for its own erosion.
Now, the consensus reaction to a story like this, the one already calcifying into conventional wisdom across the trade press and the investor memos, runs roughly as follows: model capability is leaking everywhere, distillation is unstoppable, open-weight Chinese models are converging on frontier performance at a fraction of the training cost, so the real moat going forward will be distribution: owning the billing relationship, the customer, the platform, rather than owning the model itself. It's a tidy thesis and you can already see venture decks built around it: "we don't need to win on benchmarks, we need to win on workflow lock-in." Plenty of capital is being allocated against exactly that bet right now.
That thesis misses something more interesting buried in this very story: distribution doesn't actually look more defensible than the model did. Consider what the reseller economy has already proven. Every layer of access control Anthropic has added like geoblocking, phone verification, credit card requirements, biometric KYC has produced, on a roughly one-to-one basis, a corresponding evasion technique. Phone verification gets defeated by burner numbers bought for a dollar. Credit card requirements get defeated by stolen cards or by simply renting someone else's already-verified account. Biometric KYC, supposedly the unbeatable final layer, gets defeated by paying real humans in low-income countries roughly $20-30 to sit through the verification themselves, a detail that should embarrass anyone who assumed biometrics represented some hard floor on identity fraud. Given that the access layer, the precise thing the "distribution is the moat" thesis is banking on, has already proven this porous, there's no obvious reason billing relationships or platform lock-in will fare any better once they become valuable enough to attack. Nobody is reselling access to a customer relationship the way they resell tokens today, but that's a statement about relative profitability right now, not about some structural immunity. Give the resale economy another eighteen months and "reselling the access to the access" stops sounding like a joke and starts sounding like the next forum thread.
The genuinely provocative position, then, the one running against both the "models are the moat" narrative that justified the last few years of compute spending and the emerging "distribution is the moat" narrative replacing it, looks something like this: there may be no durable moat anywhere in this stack and the entire capital structure of frontier AI (the hundred-billion-dollar training runs, the valuations premised on winner-take-most dynamics) is being priced as though a moat will eventually congeal once the market "matures," the way moats congealed in search, in social networks, in cloud infrastructure. That congealing might simply never happen here, because the conditions that produced durable moats in those earlier markets (network effects that compound with scale, switching costs that genuinely lock users in, data advantages a competitor can't reconstruct) don't obviously carry over to a product category where the entire value proposition can be approximated just by observing enough input-output pairs. These models are, at bottom, very complex but theoretically approximable functions: feed in enough prompt-completion pairs and, per universal approximation arguments dating back to Stone-Weierstrass, you can reconstruct something close enough to the original function to compete with it commercially, without ever touching the original weights. Google's search ranking earned its defensibility by being a continuously updating process wired into a live, exclusively-owned index of the entire web - you couldn't approximate Google by sampling its outputs, you'd have to rebuild the index, which meant rebuilding Google. A language model carries no equivalent moat-by-process. It behaves more like a static function that anyone with enough patience and enough scraped transcripts can eventually reverse-engineer to "good enough," and the entire Chinese resale economy, however unflattering to look at directly, amounts to a distributed, crowdsourced function-sampling operation, funded by unwitting Western subscribers, running in real time.
Follow that logic and the long-term winners in this industry might end up being neither the labs burning billions on ever-larger training runs, betting that scale itself becomes the moat, nor the platforms hoping to own the customer relationship and monetize through workflow lock-in, betting that distribution becomes the moat once capability commoditizes. The winners might instead be the unglamorous arbitrageurs sitting in the gaps between currencies, sanctions regimes and enforcement jurisdictions, extracting margin precisely because the underlying market stays too geopolitically fractured to ever fully integrate into one clean, enforceable pricing structure. That conclusion sits uneasily with anyone who'd rather believe frontier AI tells a story about scientific breakthrough compounding into durable competitive advantage. A hundred-billion-dollar industry is having its retail pricing arbitraged by guys running browser automation scripts out of rented servers and the most economically rational actors in the entire value chain right now might not be the people building the models at all. They might be the ones buying $200 subscriptions and reselling them ninety percent off.
Intel: https://news.ycombinator.com/item?id=48667495