[시블] 스팀 개발팀은 무엇을 하고 있나
2사분기는 6월 말 까지입니다.
3사분기는 9월 말 까지입니다.
2017 로드맵 중 2사분기에 끝내겠다던 것들 중 완료된 것
- 드래그 앤 드롭 이미지 업로드
- 글 보상을 글쓴이, 개발자, 운영자가 나눠갖는 기능
2사분기 계획중 완료 안된것
- 글쓴이가 자기 글의 댓글 관리(블록체인엔 남고 프론트 엔드에서만 삭제)
- steem.io 공식 홈페이지 개편
- developer.steem.io 개발자 페이지 신설
- 공식 클라이언트 라이브러리 (steem.js 가 있긴 있는데 문서 및 샘플코드 부족)
3사분기에 마치기로 계획된 것들
- 커뮤니티 기능
- Foursquare 나 Stack Overflow 처럼 닉네임 옆에 휘장 표시
- 상단 상태바에 여러가지 알림 표시
- 써드파티 개발자가 스팀 회원가입 받을 수 있도록 지원
이것들이 처 놀고 자빠져 자느라 이런 딜레이가 발생하는 것일까? 하는 의구심이 생기게 됩니다.
시사와 블록체인

뭐하느라 이렇게 조용한가?
19일전의 공지사항에서 조금 힌트를 얻습니다.
https://steemit.com/steemit/@steemitdev/help-us-test-new-performance-optimizations-for-steemit-com
steemit.com 의 확장성(더 많은 동시접속자를 받아도 느려지지 않기 위한)을 보강하는 개발이 진행중인데
개발 진행은 이곳에서 확인할 수 있습니다.
https://steemitstage.com
- 블록체인에서 직접 쿼리하는게 아니라 elasticache/redis 에 cache 된 읽기전용 데이터를 가져오므로 속도 개선
- 웹소켓 방식은 대규모 접속요청에 대한 로드밸런싱이 어려워서 로드밸런싱이 잘 되는 HTTP/JSONRPC 방식과 웹소켓방식을 혼용
쉽게 설명하자면
블록체인에 데이터가 기록되는 방식은 데이터를 빠르게 읽기 위한 목적이 우선이 아니라 올바른 데이터가 들어가 있는지 검증이 우선입니다. 여러명이 동시에 접속하면 쉽게 느려지게 됩니다.
그래서 데이터를 빠르게 읽어들이기 위한 서버를 따로 만들어서 빠르게 응답할 수 있도록 합니다.
로드밸런싱은 서버가 여러대 있을 때 사용자가 접속 요청을 하면 사람이 적게 몰린 서버로 연결해줍니다
한마디로, 더많은 접속자에 대비해서 속도개선 잘 하겠다는 얘깁니다.
14일 전의 글도 보시죠. 이번엔 웹서버 캐싱 말고 스팀 블록체인 관련 얘기 입니다.
https://steemit.com/steemitdev/@steemitdev/steem-blockchain-update-august-2017
지난 몇달간 바빴다. 하드포크 20은 몇달 후에 하겠다. 지금은 블록체인의 확장성을 위해서 근본적인 부분을 고치는 중이다.
현재 아마존 웹서버에서 스팀 풀노드를 7개 돌리고 있으며 앞으로 더 늘려야 할 것이다. 핵심적인 문제는 Steemd 풀노드가 싱글 스레드로 돌아가므로 멀티스레드 CPU의 이점을 활용하지 못한다는 것이다.
steemd 서버 프로그램이 가스렌지라고 생각해보자. 버너 한개가 있고 지금 요리를 해야된다고 치자. 음식을 기다리는 접시들이 피어 투 피어 네트워크다. 블록을 받아들이고 숫자를 해석해서 steemit.com 같은 사이트의 API 요청에 응답한다. 솥과 프라이팬과 냄비가 하나의 버너를 바쁜순서대로 돌아가며 사용하면서 요리를 해나간다. 주문 수량이 많아지면 steemit.com 은 서빙을 느리게 할 수밖에 없다.
지금까지 우리는 버너 한개짜리 가스렌지를 여러개 추가해서 늘어나는 주문을 감당해왔다. 블록체인들은 처음부터 이런식으로 설계되어 있었기 때문이다. 그러나 이것은 이상적이지 않은데 왜냐하면 우리의 가스렌지(컴퓨터)들은 사실 8개의 버너(CPU)를 가지고 있고 우리는 그중 한개씩만 사용해온 것이다. 8개를 동시에 쓰는 것이 효율적이다. 불 위에 냄비 올리고 그 옆에 불에 솥 올리고 그 옆에 프라이팬 올려서 동시에 처리하는 것이다.
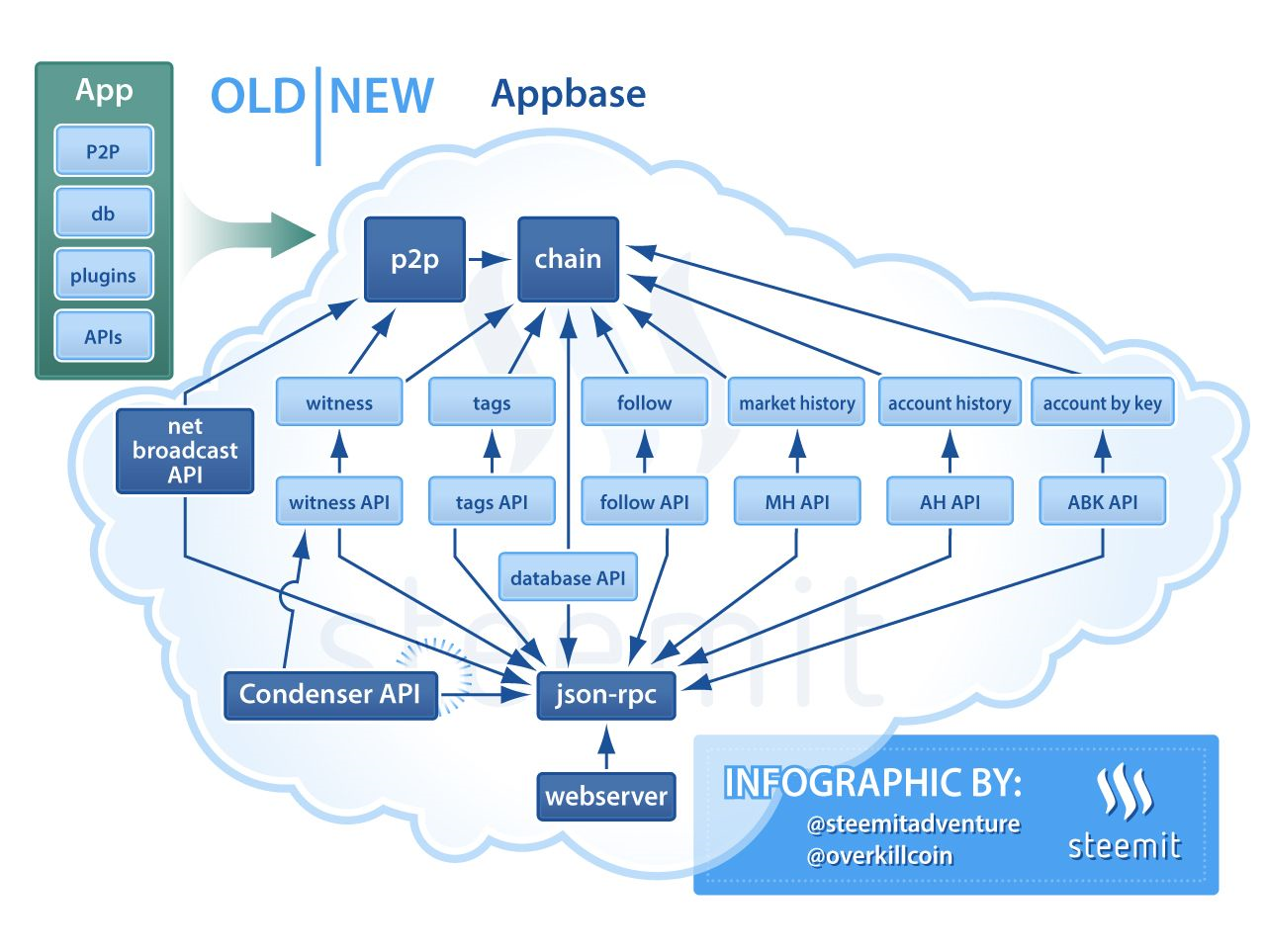
그전까지는 하나의 프로그램에서 p2p 코드와 데이터베이스와 플러그인들과 API 처리를 다 했었다.
이제는 모든게 플러그인으로 쪼개져서 다른 플러그인들과 필요에 따라 직접 커뮤니케이션을 한다. 이렇게 모듈화가 잘 되면 개발이 더 빨라지고 코드리뷰가 쉬워지고 병렬처리가 더 효율적으로 된다. 컴포넌트를 넣고 빼고 하기도 쉬워진다.
테스트 결과 API 요청을 5배 더 처리할 수 있었다. 기존의 API들은 그대로 호환되도록 놔두고 새로운 condenser_api 라는 것을 추가했다. jsonrpc parser를 jsonrpc 2.0 표준에 맞게 다시 짰다.
기술적으로 어려운 작업이었다. 미래의 모든 확장성을 다 수용할 수 있는 탄탄한 기초가 될거라고 확신한다. 그 다음에는 여러분들이 보고싶어하는 기능들을 구현하는데 집중할 것이다.
말하자면
우리가 눈으로 보고싶어 하는 기능들은 계획보다 늦어지게 생겼고
그래도 뭔가 어려운걸 하고있긴 하다는 얘기인데
믿거나 말거나는 각자의 판단에 맡깁니다.
이것들이 처 놀고 자빠져 자느라 이런 딜레이가 발생하는 것일까?
ㅋㅋㅋㅋㅋㅋㅋㅋㅋ 항상 너무 재밌으시네요
좋은 정보 감사드립니다
ㅎㅎㅎ
8월은 휴가도 있었을테니 좀 봐주죠(?) ㅋㅋ
새로운 정보네요 감사합니다^^
This is impressive stuff.
좋은 정보 감사합니다. 하드포크 20을 기다리고 있는 입장에서 얼마나 진행되고 있는지 궁금해하던 참이었습니다. 제가 태국으로 휴가를 갈 예정인데, 스팀티를 입고 돌아다니는 사람이 있다면 저라고 생각하시면 될 것 같습니다.
그냥 놀지는 않겠지하고 생각하고 있습니다
똑소리나네요!
알고 싶은 것..궁금했던 것.. 핵심을 찔러 알려주셔서 감사합니다^^
You're a true professional.
어머.. 매일 공부하시나봐요..
좋은 블로그감사해요.
팔로우 업보팅하고 갑니다
저블로그도 한번 와주실거죠 ?? ^^
명쾌하고 유익한 포스팅 감사맙니다
좋은 정보 감사합니다! 팔로우하고 또 좋은 소식 기다리겠습니다. ^^
좋은 정보 감사합니다. 전 프론트쪽의 기능개선보다 이런 HA를 위한 노력이 더 중요하다고 보는 입장이라 스팀이 잘하고 있다고 생각됩니다
백엔드 아키텍쳐가 무척 궁금했는데, 글 감사드립니다. 우선 백엔드에 cache layer가 없었다는게 충격입니다. 이제라도 넣었다니 다행이네요. 그리고 지금 수준의 인터페이스에서 웹소켓은 오버킬 아닌가 생각도 드네요. 장기적으로는 필요하겠지만..