Full Node Configuration Testing
It's incredible to think that we have been running the mainnet for almost 2 months! In that time we have been able to gain a much better understanding of the performance of the EOS application.
Full Nodes
To date, the most problematic node type for the network has been Full nodes. These are the public facing RPC API nodes that all users and dApps interact with. There is a lot of strain on these nodes as they store and process more data than any other node type and are computationally expensive due to the nodeos app being single threaded.
One of the main culprits for Full node failure is down to the use of the filter-on: * config. With the wildcard, the node will attempt to store all smart contract data. There are a couple of contracts which are generating large amounts of data (spam?) into the network. Take a look at this chart:
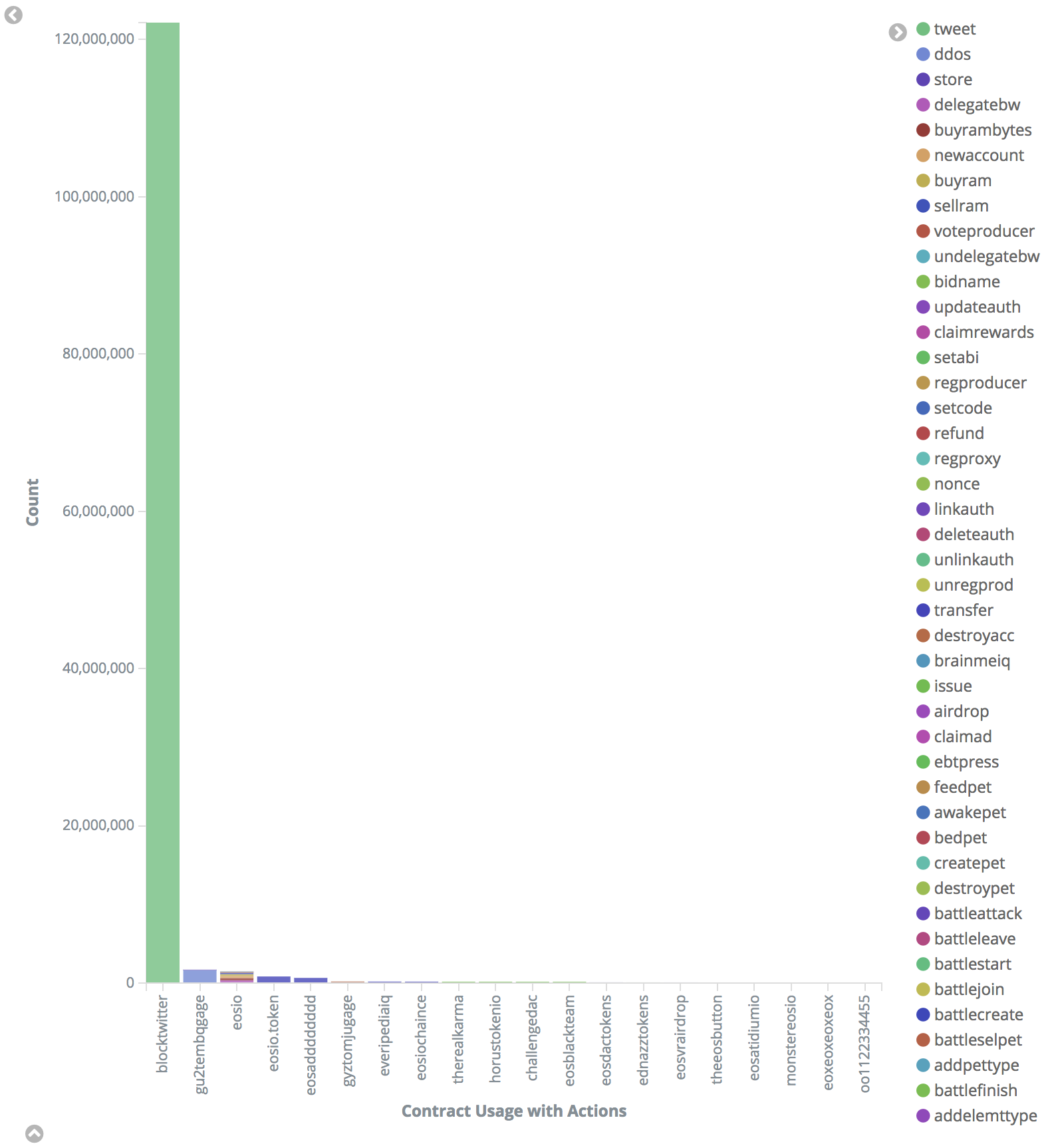
This chart shows the top contracts with their associated actions. Notice how the top two have more activity than the eosio system contract actions! Well, by using the filter-on wildcard, all of this data will be taking up precious RAM and processing resource on the Full nodes.
If we remove blocktwitter and gu2tembqgage from this chart, the landscape looks more healthy:
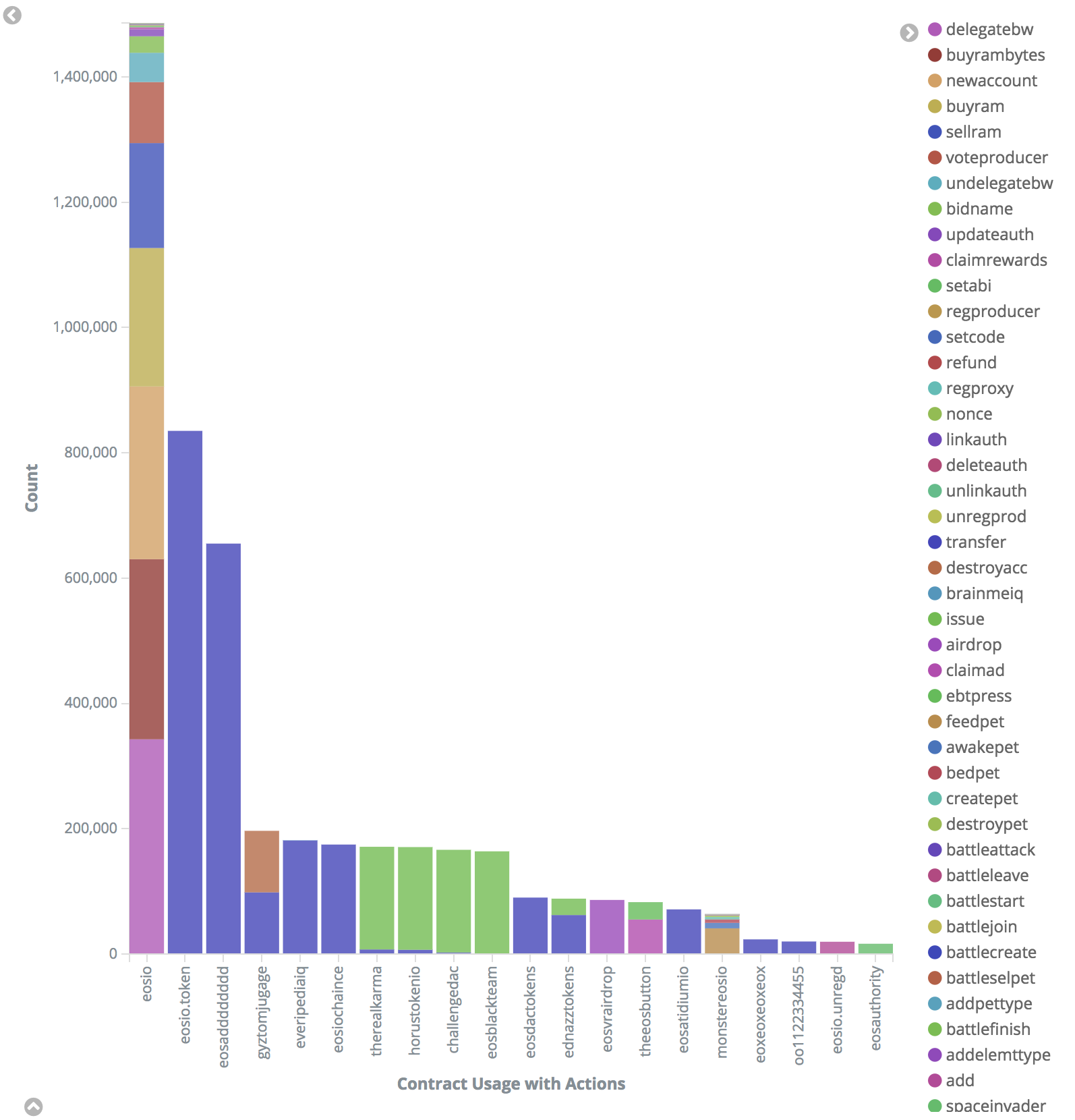
The problem is that using a whitelist of contracts for filter-on could result in legitimate new dApps not having their contract data available via major Full nodes throughout the chain. To combat this, a new config switch has been devised: filter-out. This will allow BP's running Full nodes to maintain a wildcard for all contracts, but to specifically ignore contract actions from known spam accounts.
This certainly helps with system resources but it's a tricky subject, as this decision is down to the discretion of the BP's and there is no consensus methodology in place for who should be added to this list.
Performance Tuning
At Block Matrix, we have been A/B testing various difference system configurations to determine what increases performance and/or lowers system resource utilisation. There is one configuration improvement that has had more immediate impact than any other: separate disk mount for data directories.
Across all of our nodes, we now have a separate mount for the blocks and statedata directories. We moved from storing these directories on our Ext4 O/S partition, to having a dedicated XFS mount which we found gave us the best combination of performance and reliability.
We initially moved 50% of our 6 node set across to this setup, and it's easy to see the impact this had:
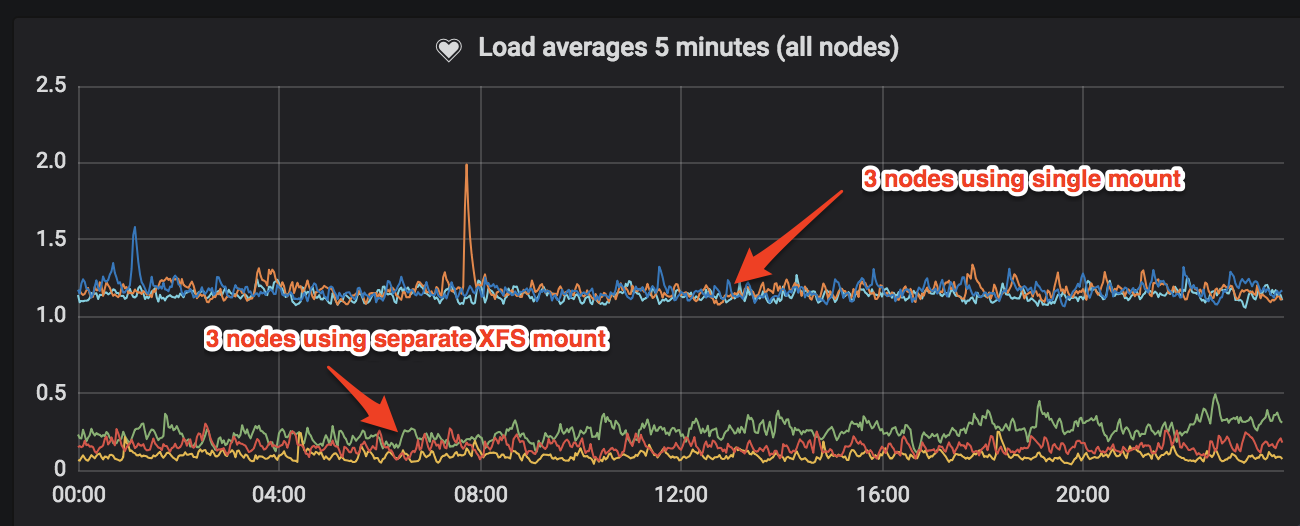
We use Telegraf agent on each node which bubbles up stats to Grafana via InfluxDB, this allows us to monitor all system resources but it's easily configurable for application monitoring too.
After 2 weeks of testing, we are now confident in moving all our remaining nodes to this configuration, if you give this a try or already have a configuration like this in place, we'd love to hear about it, especially the filesystem you're using!
For the techies out there, here is our current fstab:
/eosdata xfs noatime,nodiratime,attr2,nobarrier,logbufs=8,logbsize=256k 0 0
Moving Forward
There are many other improvements and techniques that we have planned for testing, it is extremely important that we don't rely on scaling vertically to handle the ever increasing demands from the network. Emerging tech such as Optane drives is exciting, but it is imperative that the nodeos application is continually improved to use all available resources on the host machine.
Block Matrix are currently a paid standby BP for the EOS network. We are super passionate about the EOS project and are focussed on creating robust infrastructure and open sourcing everything we build to support the network and the wider community.
It would require a little more setup, but you could minimize ram requirements and processing if you ran one nodeos dedicated to RPC requests (minus push_transaction) with the
filter-on = *for history_plugin andread-mode = head.And ran another for handling push_transaction without the
filter-on = *. This of course would require a proxy to route the requests.Update: Actually a proxy is not necessary as nodoes will forward on the transaction to other nodeos.
Oh cool, will give this a go - thanks for the info!
"we now have a separate mount for the blocks and statedata directories"
so blocks and statedata share the same mount?
would it improve even farther to have blocks and statedate on separate mounts?
Yes, absolutely! This has been tested by some of my fellow BP's and works well.