Chasing shadows: Is AI text detection a critical need or a fool's errand?
Before I start on today's article, let me give you a quick reminder of my last one. Have you entered your observation into the Globe At Night application or web site? The current campaign ends in just 4 days, on April 9. For me, we've had cloudy skies all week, so I plan to make an observation this weekend. It looks like skies should be clear tonight and tomorrow.
Now, on to today's topic:

Image by Microsoft Copilot
Summary
There is an interesting article in this month's Communications of the ACM, The Science of Detecting LLM-Generated Text. The article is a fascinating review of the state of the art with LLM text detection, but I can't help but wonder if the whole idea that we can ever detect AI generated text reliably is really just an exercise in tilting at windmills?
In the end, maybe the problem comes down to the simple observation that people lie sometimes. In all of human history, it has been difficult to determine when people are being honest or lying. I'm not sure if technology can change that.
Although my tone here may sound skeptical about the future of reliable AI text detection, I definitely recommend reading the article and watching the video that was posted with it:
Note that for brevity in this article, I will use the acronyms "AI" and "LLM" interchangeably. In the real world, that's not exactly right.
Introduction
When I was in elementary school, the calculator was just seeing widespread consumer adoption. The calculator of the day could only do addition, subtraction, multiplication and division, but it was already a threat to the education system. As far as I remember, there was absolutely no controversy at the time. Children should memorize their multiplication tables (up to 12x12), and arithmetic should be done with pencil and paper - even long division. Using a calculator (or a slide rule) was a form of cheating.
As I got older, these ideas started to be controversial. Why should children do tasks that a calculator could do for them? And how could the teacher even know? If a child brings their arithmetic homework in with the correct answers, how could the teacher know whether those answers were produced from the child's mind or by a calculator? Maybe a child's time would be better spent learning other things that couldn't be automated with a calculator?
By the time that @cmp2020 was in elementary school, the controversy was over and the calculator had won. I guess the kids at some schools might still memorize the multiplication tables, but the calculator is now their companion throughout the entire education experience (many of them also don't know how to tell time on an analog clock, but that's a topic for a different day. 😉)
In some ways, I'm starting to feel that the path to detecting AI generated text might follow the same course. Maybe what matters isn't whether the text was composed by a person or by a machine. Maybe what matters is the message that it conveys. Does it convey interesting, accurate, and useful information? Maybe the real "intelligence" isn't in writing the words, but in choosing the topics and deciding which words, phrases, and paragraphs to include or exclude.
Against that backdrop, here's some of what I learned from the article followed by some additional discussion.
AI detection is desired in order to minimize risk and fulfill AI's potential
In the article, Ruixiang (Ryan) Tang, Yu-Neng (Allen) Chuang, and Xia (Ben) Hu argue that the ability to detect LLM generated text is a critical need because AI can only reach its full potential if detection tools are able to minimize the risks from things like, "phishing, disinformation, and academic dishonesty". To date, the authors suggest that AI's potential has been hampered because of these risks.
Accordingly, the authors describe their goal for the article, as follows:
We aim to unleash the potential of powerful LLMs by providing fundamental concepts, algorithms, and case studies for detecting LLM-generated text.
An overview of detection types
The authors provide a taxonomy of AI detection techniques that starts with two branches at the top. These are black box and white box. A black box technique is one where the detector only has access to the output from an LLM. A white box technique is one where the detector is able to affect the text that the LLM produces.
The tools that Steem curators are probably familiar with would be "black box". These would operate by checking the frequencies of words, phrases, and sentences in an article and comparing those frequencies against texts that are generated by humans and also against texts that are generated by LLMs. Based on how close the comparisons are, the detector gives back some level of confidence about whether the text was created by man or machine.
On the other hand, white box techniques operate by intentionally creating the text in a way that can be recognized by a detector. Simplistically, this can be thought of as putting a coded message into the text that can only be read by the detector, and says, "this document was created by an AI."
You can click through to the article to learn about each of these techniques in more detail.
In order to determine the effectiveness of these tools, researchers use a variety of benchmarking datasets which have been collected and published. These include the following:
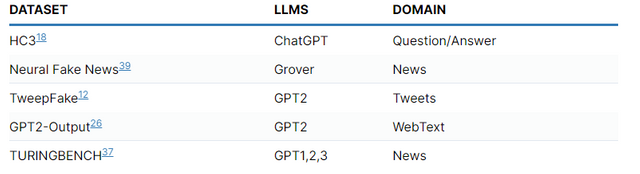
Challenges to success
One of the key benchmarking challenges arises from the speed of development in the AI sector. Despite the ongoing work on benchmarking, detection researchers are challenged to keep up with the pace of LLM advancement, and there are no comprehensive benchmarks datasets that can keep up with the wide array of LLMs that have been created.
Another challenge stems from adversarial attacks. An example comes from Can AI-Generated Text be Reliably Detected? by Sajith V Sadasivan and colleagues. As described, this technique reduced white box detector accuracy from 97% to 80% and black box detection from 100% to 80%. In this attack, LLM output from one model is sent to a different LLM model for paraphrasing prior to being delivered to the detector.
The authors also raise other concerns. For black box detectors, the authors point out that the tools are vulnerable to bias problems in the training data. For white box detectors, the authors observe that there is a general tradeoff between the quality of the text and the watermark's efficacy. Further, white box models are susceptible to being reverse engineered by a determined prompt engineer.
Additionally, the authors suggest that the research into assessing confidence levels is sparse. We would like to be able to say that a text with a 95% confidence score of AI generation is more likely to have been created by an LLM than another text with a 50% score. Unfortunately, the research into these confidence scores is thin. Further, the methods for determining accuracy are subject to false positives and false negatives, and they may be biased against certain populations, such as non-native users of the language.
Finally, the explosion of open source LLMs makes the task of detection research all the more difficult. The authors even suggest that the explosive growth of Open Source LLMs will eventually render black box techniques ineffective.
Discussion
In all, this video and article gave a fascinating overview into the state of the art on detection of AI-generated text. The authors definitely argue for a popular position when they say that the ability to detect AI-generated text is critical.
Certainly, I agree with them that we need to minimize risks like "phishing, disinformation, and academic dishonesty". But these problems are not new with the arrival of AI. I am starting to believe that reliably detecting AI generated text will eventually be equivalent to asking whether an arithmetic solution was "created" by a calculator.
LLMs are getting better and better, and it's trivial to imagine future adversarial attacks (instead of using one LLM to paraphrase a text, use two, or three, and so on; interweave sentences from two separate LLMs; intentionally insert typos/spelling errors, etc...) In the end, I think maybe we're just going to have to understand that there's a human owner of the text, and that person is ultimately responsible for what was said - regardless of whether an LLM was used as an intermediary. Then, the risks of "phishing, disinformation, and academic dishonesty" would be addressed by ethics and laws, not by technology - as they have always been.
In closing, as a firm believer in the maxim that any problem can be made worse by adding government, the last seconds of the video illuminate my biggest concern with the technologies:
However, the challenge is that how could we design these stealthy and robust watermarks into the LLM generated text, and how could we force all these big companies to add these watermarks into their products? So that will be a very challenging question. So definitely we need to collaborate with governments to have policies and laws to further regulate the use of these powerful generative AIs.
Thank you for your time and attention.
As a general rule, I up-vote comments that demonstrate "proof of reading".

Steve Palmer is an IT professional with three decades of professional experience in data communications and information systems. He holds a bachelor's degree in mathematics, a master's degree in computer science, and a master's degree in information systems and technology management. He has been awarded 3 US patents.


Pixabay license, source
Reminder
Visit the /promoted page and #burnsteem25 to support the inflation-fighters who are helping to enable decentralized regulation of Steem token supply growth.
I find the entire LLM and AI landscape fascinating. I’ve already set up my own privateGPT which allows me to use an uncensored LLM and I’m now experimenting with training it with my own dataset. Which is going very badly.
GPT-4 (paid-for which I don’t have) allows people to upload their own training data - training data that can be generated using a web scraper of any website (all available for free on GitHub). This is where I can’t see any detection tool ever being reliable. You can even program it to “talk like (name)” which could be the person you’ve trained it to be.
As you suggest, it’s like trying to identify if maths homework used a calculator or not.
Even the idea of getting an identifiable “watermark” would be easily circumvented via privateGPTs.
It’s probably a very interesting area to research if you’re lucky enough to get paid to do it!
I tried setting up LLM Studio but it crushed my computer. One of these days, I'll modernize my hardware and try it again. The censorship, CYA, and scolding from big-tech's free implementations are insufferable.
To me this is the biggest tragedy of the way that many of Steem's high-powered curators are curating. We're missing out on a massive opportunity that we should have been perfectly positioned for. If curators were valuing posts correctly, Steem would be an ideal platform for AI training and implementation, which could massively increase the value of the tokens. Instead, they're flooding the database with noise that's basically worthless if you're training for things that appeal to humans --- or do anything useful for that matter.
Agreed. On the "detection" side and on the "adversarial attack" side.
I haven't tried LLM Studio yet - do you have the option of using your GPU for processing?
The PrivateGPT that I set up was much quicker with the GPU, even using my laptop. It was a pain to set up and took me pretty much a full day because of the GPU needing CUDA in my WSL environment. So tricky, that I deleted it all and gave up but tried a 2nd time which went more smoothly.
A very quick local GPT would be to use Ollama - there are a few uncensored models available and it's about 3 or 4 command lines to install and run.
That's perhaps reflective of the majority-community perspective that AI generated content is bad. Full stop. There are only a handful of us now who want to do something different - the herd appear to be happy with their diary games and engagement challenges and choose not to look (or think) beyond that. Maybe aspiring to be a curator or representative themselves, or run a community. Nothing beyond "the template".
I don't remember, and I've already uninstalled it. If I get motivated, maybe I'll reinstall it and check. My PCs are so old, I think I'll need to modernize, though.
Yeah, true. And, to be fair, AI right now is very easy to misuse here. It's a conundrum.
I like the topic and I agreed with you that we need a different approach to dealing with "AI".
The comparison with the pocket calculator is very apt. In the meantime, our sons' grammar school uses a computer algebra system in lessons. Why should pupils have to (repeatedly) draw graphs or repeatedly calculate derivatives or zeros when an app can do it much faster and more efficiently? Of course the methods need to be known, but do you have to repeat them x times? That bored me even as a pupil. In the time saved by using the app, you can perform completely different mental feats...
I see it similarly with the language models: The human provides the concepts and the "AI" formulates this, helps with structuring, etc.
That would of course be the ideal situation.
A kind of watermark would be very interesting. However, gorilla's argument that this can be circumvented with private language models cannot be dismissed out of hand.
The fact that this is possible in principle is shown by research into the protection of copyrighted material through invisible modification, so that "AI" cannot use this as training data (I can't find the link for this at the moment).
Unfortunately not yet. I haven't had any motivation in the last few days (I even switched on my PC today for the first time in several days) and now the sky is full of clouds. But as I have seen, there are still some campaigns to come :-)
That's how I am starting to see it, too. Another thing that occurred to me after posting is that AI writing styles are nearly certain to influence human writing styles. It's not a 1-way street. Even things that are written by humans may start to resemble AI texts.
Watermarking (i.e. white box techniques) is great for AI that wants to be recognized, but yeah with Open Source and private models, I can't imagine a way to make it universal. At some point, I think we'll just have to assume that everything we're reading was written or assisted by an LLM.
I was counting on clear skies last night, but I didn't get them. Maybe tonight.
Why would you do that...
Ugh... Now I am tempted to write a page-long comment but I will refrain from doing so!
The only thing that I would highlight is from your reply to a comment:
I think you are also referring to the moderators here!
Loved your article. I didn't understand some of the very technical elements though!
P.S.: I never understood the "human-written" label. Make some typos. Write "i" in place of "I" and "Voilà": The text is most likely human-generated! Passed the test with flying colors. Or in some cases, the deliberate effort to not use correct grammar (pure laziness) and flaunt many typos because: We are the proud human writers. No, you are only getting away with the human-written/ non- AI label where you should have made a bare minimum effort to write something that should be called an article!
Ha, I laughed at your P.S. You're right. If someone's going to post a fake article, I don't think they'd hesitate to post a fake label to go with it. 😉
Yeah, I wasn't thinking of anyone in particular. Just the general mismatch in many posts between their reward-value and the appeal of their contents. It would make the job of AI-training difficult or impossible.
Upvoted. Thank You for sending some of your rewards to @null. It will make Steem stronger.
TEAM 1
Congratulations! This post has been upvoted through steemcurator04. We support quality posts, good comments anywhere, and any tags.Thank you, @o1eh!