Programming Diary #15: Voting suggestions and author incentives
Summary
Right on schedule, two weeks after Programming Diary #14: Historical graphing and helpful descriptions, I'm back with another programming update. This post will describe my programming activities during the last two weeks. Once again, I worked mostly on my toy Steemometer program, and also did a (very little) bit of python work on the mod-bot program from @cmp2020.
For the Steemometer program, I made 8 git commits in order to add filtering of burned beneficiary posts and also created a new "Suggested Vote" option. These commits also covered some additional troubleshooting of the displayed "operations per minute" values and for crashes that the program was encountering.
For @mod-bot, I made one change to @mod-bot's "mention handling" (we'll see how that worked when I post this), and also made the fix that @moecki alluded to in this comment - relating to a problem that was described in my previous post,
Sometimes Steemchiller adds or changes fields with the result that the number of "columns" and order changes.
For this he adds the entry cols. The safest way to access the data is therefore e.g.: rows[0][cols["author"]].
Then the order doesn't really matter and only a change in the field name can cause complications.
However, he announces this early on.
Background
Continuing my bi-weekly practice, I'll start with my stated goals from Diary #14, so here they are:
The new goals are:
- Create minimum value filters for posts that appear in the VAAS section of the display based on at least these criteria: 1.) author reputation; 2.) number of followers; 3.) median reputation of followers.
- Offer suggested voting percentages for posts that appear in the VAAS section based on the same criteria, as well as other criteria like the number of words and the current payout value.
And once again, I completed both goals. Additional refinement is still needed, however, because I need to sort out exactly what factors are important. What I implemented in the last fortnight for these goals was definitely a barebones solution.
Additionally, as I mentioned in the previous diary post, the numbers that were being displayed after I added the 5-minute history seemed implausibly low. Finally, the window started experiencing intermittent crashes.
So those are the Steemometer topics that got my recent attention. Additionally, I updated @mod-bot so that it would (hopefully) ignore non-command mentions from moderators in its monitored communities, and I made a change to its python code so that it will automatically recognize any future change in ordering from the SDS call where it encountered the problem.
The mod-bot changes weren't really substantial enough to write more about, but let's look at the Steemometer changes in more detail.
Progress
Filtering
Of course, it's not really possible to visualize filtering, since the posts are excluded. The current rules, however, are that a null beneficiary post won't appear if any of the following conditions are true:
- The author reputation is less than 45.
- The author has less than 20 followers
- The median reputation of the author's followers is less than 35
For now, I decided not to add filtering to the vanity messages or promoted posts, since SPAM has not (yet?) been a problem in those displays.
Vote suggestions
I added a "Suggest Vote" button that only appears when a null beneficiary post is being displayed. Here's what it looks like, along with the pop-up window that it brings up when pressed.
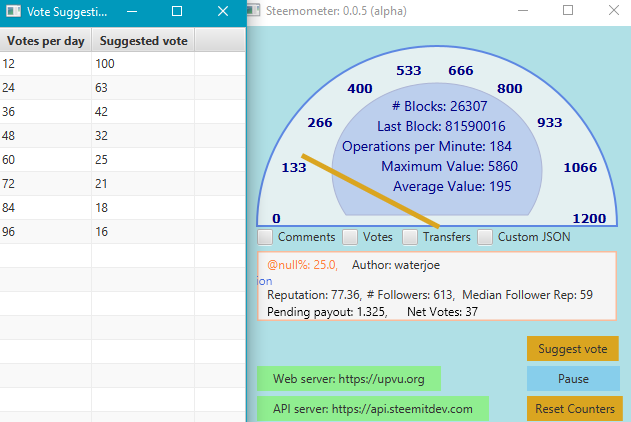
And here's the result for a different post, where the author has fewer followers:
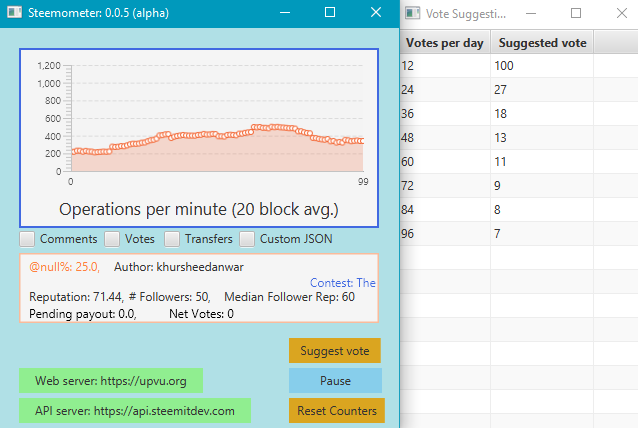
The main idea here (since we don't have a view counter) is to provide better rewards to authors who have stronger follower networks (based on follower counts and reputations of followers).
Calculating the suggested vote
The suggested vote calculation is done in two steps. First, it calculates a sort-of index value based upon the particular post that's being displayed. Next, it scales that value, depending on how many votes per day the voter is targeting. The (very rough) target is to maintain the voter's voting power at a level near 80%.
Step 1
Here is how the index is calculated
voteIndexValue = (( authorReputation - 25 ) / 75.0 ) *
(Math.log( followerCount) / Math.log(2)) * /*** <-- log_2 (followerCount) ***/
( ( medianFollowerRep - 25.0 ) / 75.0 ) * ((1 + nullWeight) / 100 );
In plain English, it incorporates the author's reputation, the number of followers that the author has, the median reputation of the author's followers, and the null beneficiary setting all into a single number whenever a null beneficiary post is displayed in the tool.
There is absolutely no rigor behind that number. It's just an intuitive scoring that seemed to line up with my expectations. I fully expect that this will need to be changed and refined.
Step 2
The second step takes that number and scales it into a table, so that the voter can choose the appropriate value - based upon expected voting activity. Here is that calculation:
for (int votesPerDay = 12; votesPerDay < 100; votesPerDay += 12) {
int voteSuggestion = (int) ((votesPerDay == 12) ? 100 : Math.round((2000.0 / votesPerDay) * voteIndexValue));
}
Basically, if the voter is voting 12 times per day (or less), they have no flexibility. All votes should be 100%. If the voter is targeting a bigger number, it divides 2000 by the daily number of votes, and multiplies that by the score that was recorded in step 1.
Again, there's no rigor behind this number. It just sort-of looks "right" when I examine the output.
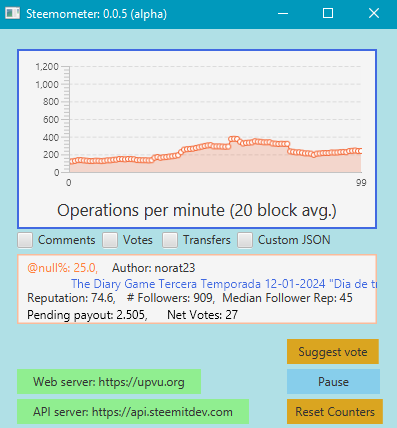
Implausibly low results in previous graphs
Looking more carefully at the numbers, I determined that my previous hunch was correct, and the numbers were too low. It turns out that it was accidentally averaging over 5 minutes instead of just 1 minute. That has now been fixed and I've tried to confirm the numbers in a number of ways.
- Spot checking against the actual numbers in a block explorer
- Using debugging output to pass the raw numbers to a spreadsheet for confirmation.
- Running two Steemometer programs side by side and observing that they report identical numbers (barring network interruptions with the APIs)
- Verifying that the "Operations per Minute" number diverges from the "Average Value" number after the first 20 blocks.
At this point, I'm just about as sure as I can be that the numbers are right (aside from connectivity disruptions with the API servers). As you can see, the current 5-minute history graph looks a little more plausible than it did in my previous post.
Stability problems
For the last three or four weeks, the program has been crashing sporadically if I leave it running for hours or days. I wasn't sure if this was a problem with my computer or with the program itself, so I tried running it on a second computer where it did the same thing.
Having confirmed that the problem was in the program, I added some debugging output and found that an array index was being overrun if an author had 0 followers or if a network disruption prevented the program from querying the follower count. That bug is now fixed, and I haven't seen any other crashes. We'll see if any other stability problems turn up.
Next up
As with previous posts, I'll define two goals for the coming weeks. The caveat this time is that we lost a tree in our yard during storms this week, so I need to spend evenings and weekends cutting that up until it's cleared. I'm not sure how much spare time I'll have for programming. Assuming I can find some time, here are my goals.
- Age posts and vanity messages out of the middle portion of the window (the Visibility As A Service (VAAS) section).
- Cosmetic changes to improve the look and feel of the Suggest vote pop-up.
Additionally, I want to consider improvements to the Suggest vote logic, and think about ways to evaluate the scoring method's effectiveness (or whether that is even possible).
Reflections
I have three topics for reflection in this post: voting and author incentives; inconsistent results from Steem's API servers; and overall code organization of the Steemometer code base.
Vote suggestions and Author incentives
Between filtering and vote suggestions, the area of post quality has been the main focus of my recent attention. Basically, the curator has 5 dimensions to consider:
- Curation rewards
- The quality/attractiveness of an individual post
- The social-network strength of a post's author
- The author's contribution at the cryptocurrency layer (token burning, club5050, club75, club100, etc...)
- Daily voting power usage
In short, it's complicated. However, the Steem whitepaper makes the following argument in its section about tipping:
Steem is designed to enable effective micropayments for all kinds of contribution by changing the economic equation. Readers no longer have to decide whether or not they want to pay someone from their own pocket, instead they can vote content up or down and Steem will use their votes to determine individual rewards. This means that people are given a familiar and widely used interface and no longer face the cognitive, financial, and opportunity costs associated traditional micropayment and tipping platforms.
This argument is true for low-stake voters, but it's not really true for voters with higher stakes. The voter needs to try to balance all five of the above factors. It turns out that the cognitive effort to do Steem voting right is actually quite high.
It occurs to me that front ends like steemit.com, upvu.org, blog.nutbox.io, etc., could reduce the cognitive effort by giving their users an automatic vote calculator, so that the voter simply has to estimate how many times per day they're going to vote (as a profile/configuration setting) and decide whether or not to vote on a post, and then the front end applies the "correct" percentage at the time of the vote. By monitoring voting history and current voting power, maybe the front-end could even eliminate the need to estimate a daily target for number of votes.
In the case that I implemented above, I think it's interesting to think about the author-specific factors: reputation, number of followers, and median follower reputation.
Reputation: Tells us the likelihood that an author's post will get more upvotes. Historically, high reputation authors have received more upvotes than low reputation authors. Ironically, as a voter, it seems to me that this number tells me more about my own chances for receiving curation rewards than it does about the post's actual author.
Number of followers: Basically, more is better. But, that's only true if the followers are organic. If we vote based on follower counts alone, the author could simply create dozens or hundreds of accounts and follow themselves in order to increase their rewards.
Median reputation of followers: I included this because it's a way to temper the ability of authors to increase their votes by creating fake accounts. Being followed by a bunch of 25 reputation accounts will drag the score down, which provides a counter-incentive to the high volume creation of astroturfed followers. Also, allocating voting power based on this value creates an incentive for an author to support his or her own followers.
One other factor of interest is this:
Post payout value: Not included yet, but what I have in mind is to halve the vote if the payout goes above $1 and halve it again if the payout value goes above $10. As with the author's reputation, this is about curation rewards.
Open questions
One observation that has surprised and concerned me as I watch the posts scrolling by is the substantial number of high reputation authors with very low follower counts. Something that could be going on is that community participation doesn't require followers, so maybe this really isn't a problem at all, but my gut tells me that having so many authors with high reputations and low follower numbers is signaling that the voters are doing something that's suboptimal. What are your thoughts about this?
What are the important factors to include? Do you think I should drop any factors that I mentioned above or add other factors that I didn't mention?
How can a method for suggested vote calculation be validated? One of the things that occurred to me is a tournament like the one that Richard Dawkins described in The Selfish Gene. That tournament was run by Robert Axelrod, and it's also described here:
Robert Axelrod: Why Being Nice, Forgiving, and Provokable are the Best Strategies for Life
Perhaps a bunch of bots could be set up to implement a certain set of rules for a period of time with an identical starting delegation, and the rule sets that earn the most rewards during the time period win? A potential problem, though, is that other voters could intentionally try to front-run or follow the bots' votes in order to influence the results.
What are your thoughts about how to validate and compare a mechanism like a suggested vote calculation?
API differences
I've written in the past about challenges with API stability or reliability, and that challenge is continuing. Steem definitely needs to beef up its decentralized infrastructure.
But, something else that I noticed recently is potentially related to what @moecki reported here. Basically, different APIs are returning different values for follower counts and median follower reputations. This can be seen in the following output:
checking remlaps-lite at https://api.blokfield.io
Followers: Median: 0
checking remlaps-lite at https://api.campingclub.me
Followers: 703 Median: 46.99
checking remlaps-lite at https://api.dlike.io
Followers: null Median: 0
checking remlaps-lite at https://api.justyy.com
Followers: 702 Median: 46.99
checking remlaps-lite at https://api.moecki.online
Followers: 703 Median: 46.99
checking remlaps-lite at https://api.pennsif.net
Followers: 703 Median: 29.01
checking remlaps-lite at https://api.steememory.com
Followers: 703 Median: 25
checking remlaps-lite at https://api.steemit.com
Followers: 702 Median: 46.99
checking remlaps-lite at https://api.steemitdev.com
Followers: 702 Median: 46.99
checking remlaps-lite at https://api.steemzzang.com
Followers: Median: 0
checking remlaps-lite at https://api.upvu.org
Followers: 703 Median: 46.99
checking remlaps-lite at https://api.wherein.io
Followers: 702 Median: 46.99
checking remlaps-lite at https://api.worldofxpilar.com
Followers: 703 Median: 46.99
checking remlaps-lite at https://steem.senior.workers.dev
Followers: 702 Median: 46.99
checking remlaps-lite at https://steemapi.boylikegirl.club
Followers: 702 Median: 46.99
The ones with 0s are probably unreachable, for whatever reason, but the ones with different numbers are puzzling. I haven't looked into the reasons behind this, but the people who are running nodes might want to sort out the reasons for these differences.
Code organization and thinking about Open Source
I've worked in the IT industry for quite some time, but I have not done extensive coding, and most of the coding that I have done was not in the object oriented paradigm. So, in addition to learning my way around Java here, I'm also learning how to think about problems in the object oriented paradigm. As a result, my code is probably not well organized. (actually, I think it's pretty bad. 😉)
At this point, I think the toy program is at a point where it could also be fun for others to run, and I'm wondering about how to open source the code. Now that I have a sort-of a target/prototype application, would it be best to rewrite the code - starting with a design for the class files, or would it be best to try slowly migrate to a better organized design over time.
I'm not sure, but I'd be interested to hear thoughts from people who have more experience with collaborative programming.
Lastly, I'm already at ~2400 words and I don't see much point to copy/pasting the Looking ahead section from post to post, so if you want to see my future plans, you can click here, but I'm dropping that section from this and future programming diary posts.
Thank you for your time and attention.
As a general rule, I up-vote comments that demonstrate "proof of reading".

Steve Palmer is an IT professional with three decades of professional experience in data communications and information systems. He holds a bachelor's degree in mathematics, a master's degree in computer science, and a master's degree in information systems and technology management. He has been awarded 3 US patents.


Pixabay license, source
Reminder
Visit the /promoted page and #burnsteem25 to support the inflation-fighters who are helping to enable decentralized regulation of Steem token supply growth.
I think this one is easy to explain - a lot of high reputation accounts have obtained their reputation by delegations or payment to a voting service. Therefore the (lack of) quality will contribute to their follower count. I was thinking along these lines as I read your criteria and wondered if you factor in bought votes into the algorithm somehow.
Tough one - I've been thinking about this quite a lot too (in my efforts to filter out shit-spam-content) - In the realrobinhood posts, steemchiller references things like Resteems and comments. These are often good indicators that a post is "better" (although once again, the caveat is comments by spammers like krsuccess).
I missed something very important from you somewhere along the line so I don't know what the final objective of this program is?
As far as simply deciding a vote percentage goes, for me, this is an impossible question because I vote in clusters. Some days, I'll pop in a vote on 20 posts (I know, sub-optimal) and other days, I'll vote on nothing and leave my "back-up auto-votes" to take over. If it's the latter, then I don't mind whether it votes on 1 post at 100% or 10 at 10%. That might be just my mindset though.
moecki was correct to dynamically identify the index location (I do the same) - it's not bullet-proof as in one update, an index changed (I can't remember what it was, but it was along the lines of "comments" or "replies" becoming "children") so it's important to keep an eye on any planned updates either way.
I can't advise you about collaborative programming - any projects that I've worked on of this nature have had very clear delineation of roles (i.e. HTML / CSS / PHP, .NET, etc.). Obviously, the cleaner and more maintainable the code, the better but even with that, every coder will code differently so rewriting large chunks might be hard to justify. Perhaps something to consider if you think it will make your job easier, rather than worrying about what other people might do.
Long term, the only way the ecosystem can really succeed is by user growth, so I think the frontends should be optimized for normies, not people who care about things like optimizing their voting power usage. Vote percentage is already way more overhead than a "like" on conventional social media.
You may want to factor the "convergent linear" aspect of the reward mechanism in, since it's nonlinear in this region.
Thanks for the reply!
Agreed. I wouldn't want the web sites to take away the option for setting a custom voting percentage, but I think it would be useful for web sites to let their users turn it on and off. What I envision is that - as a user - I could turn off the setting, then my choice would just be [vote/don't vote], and the web site would handle the percentage choices invisibly. It actually makes it easier for both normies and higher stakes voters (assuming the percentage selection is on target).
Yeah, there is definitely space for optimization. It might be better to look at post values in terms of STEEM, instead of SBD, too. That way it (hopefully) wouldn't need to be adjusted as the price of STEEM changes.
Ah, now I understand your intentions :-)
The frontend should suggest to the user which value they should vote with.
This would go in the direction of making it easy for the user and one click would be enough for the "Like".
In principle, I'm always in favour of automation, but I'm rather "old-fashioned" in this respect. Of course you can give the user the choice of switching on and off, but I personally wouldn't want to switch it on.
However, it would be interesting if the suggestion appeared in the vote bar, but I could still change it.
If I think about it briefly, I come up with the following aspects when determining the vote value (in order):
And: Exceptions prove the rule. :-))
Upvoted. Thank You for sending some of your rewards to @null. It will make Steem stronger.
This post has been featured in the latest edition of Steem News...