Proxy scrapping using Python
Here is a short and simple tutorial on how to scrap proxies using python, with requests and beautifulsoup library. In this tutorial you will learn how to scrap proxies from table in a webpage. You can also extract other datas.
Requirements:
- Python
Download from https://www.python.org/ - BeautifulSoup and Requests
Install it using terminal
pip3 install bs4 requests
Step 1.
Creating a new python file with any name. For example scrapper.py
Step 2.
Open scrapper.py, the first step is to import BeautifulSoup and requests
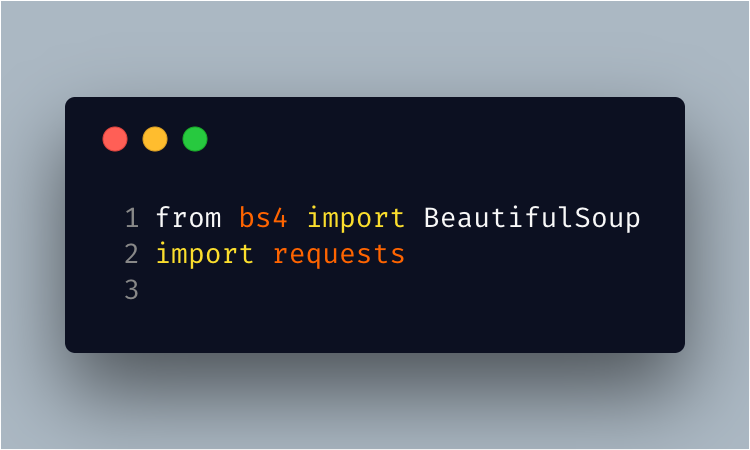
Step 3.
Enter the url of page from where you want to scrap the proxies and send a request to that page store it's content in a variable, here the name of variable is response.
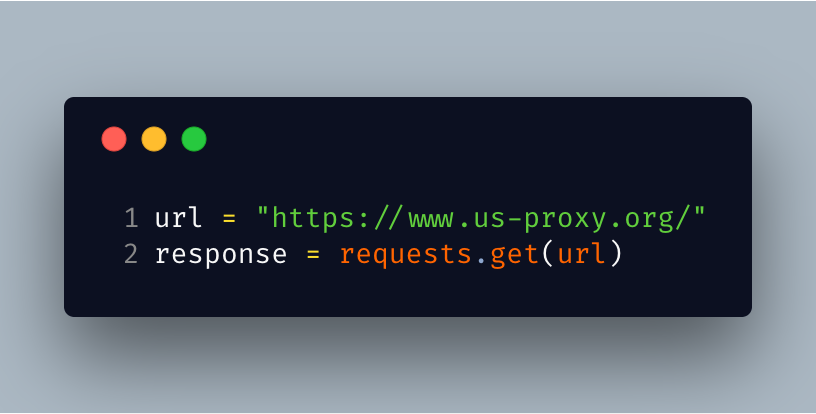.png)
Step 4.
Convert the response data into a nested data structure using BeautifulSoup. This way we can easily extract table data.
.png)
Here's how the website I am going to scrap from looks like.
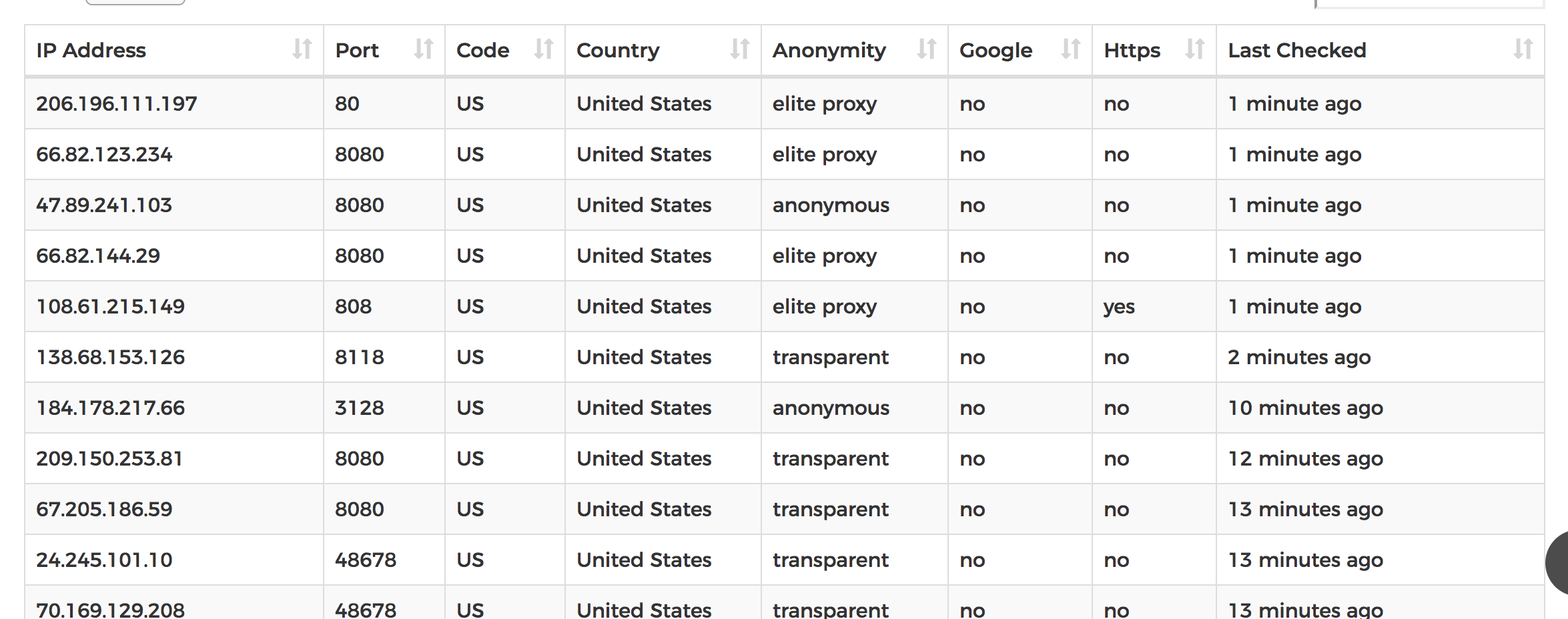
Step 5.
Find all the table rows. Exclude the first row.
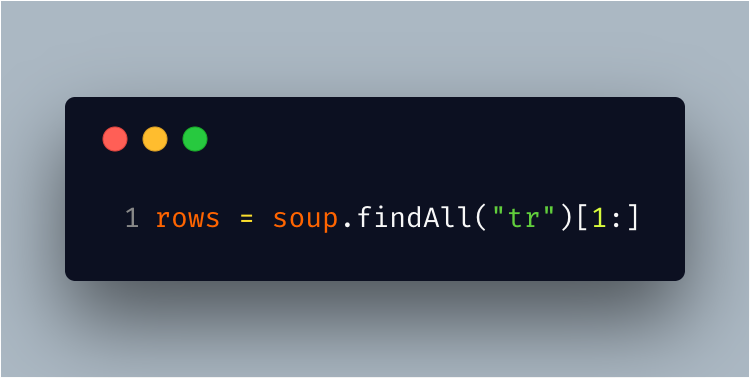.png)
Step 6.
Now since the proxy is in first and 2nd column. Therefore, loop through each row and find all the table datas in each row and print the first and second table data. Here we are printing the data in format PROXY:PORT.
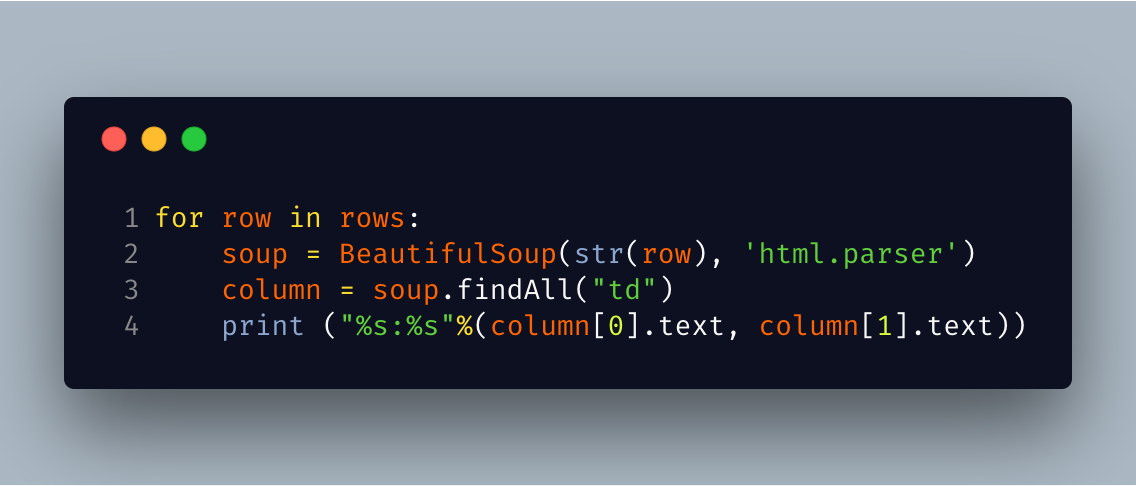.png)
Step 7.
Done. Here's how the output looks like.
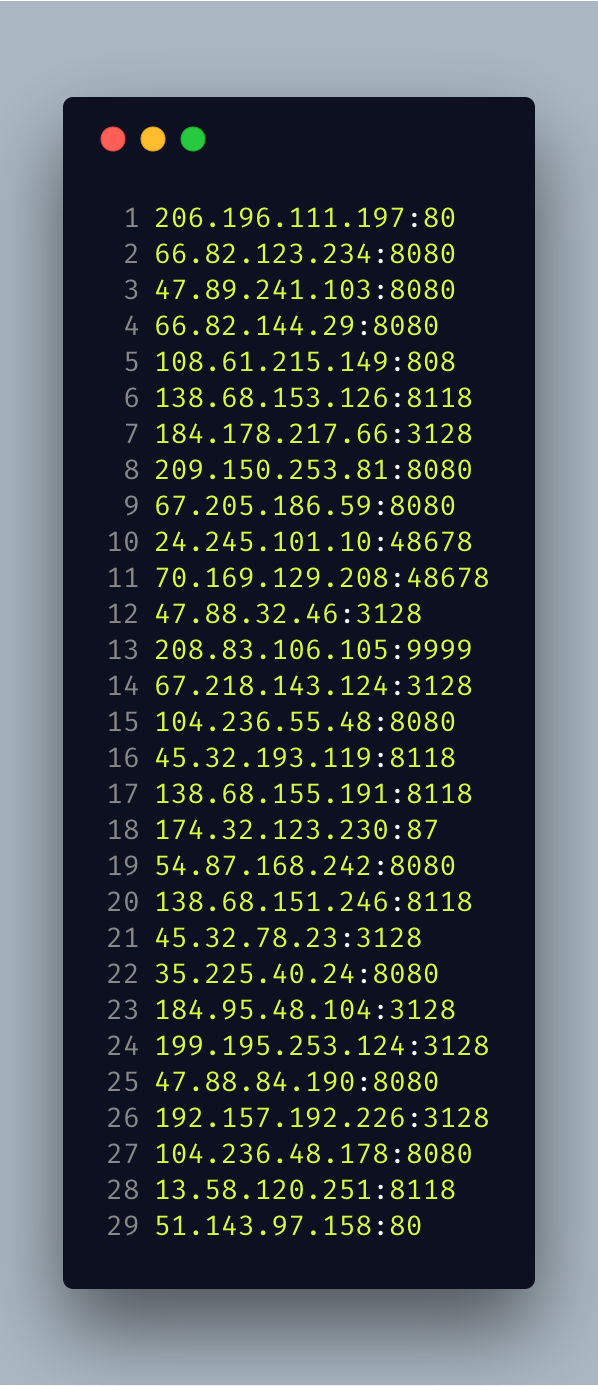.png)
Scraping Rule
You should check a website’s Terms and Conditions before you scrape it. Be careful to read the statements about legal use of data. Usually, the data you scrape should not be used for commercial purposes
If you find my post useful, don't forget to upvote it. Thank you.
I love python for these kind of things
follow +