SemanticGuard - Cuts your LLM API costs by 40-70%. One line of code
SemanticGuard
Cuts your LLM API costs by 40-70%. One line of code
Screenshots
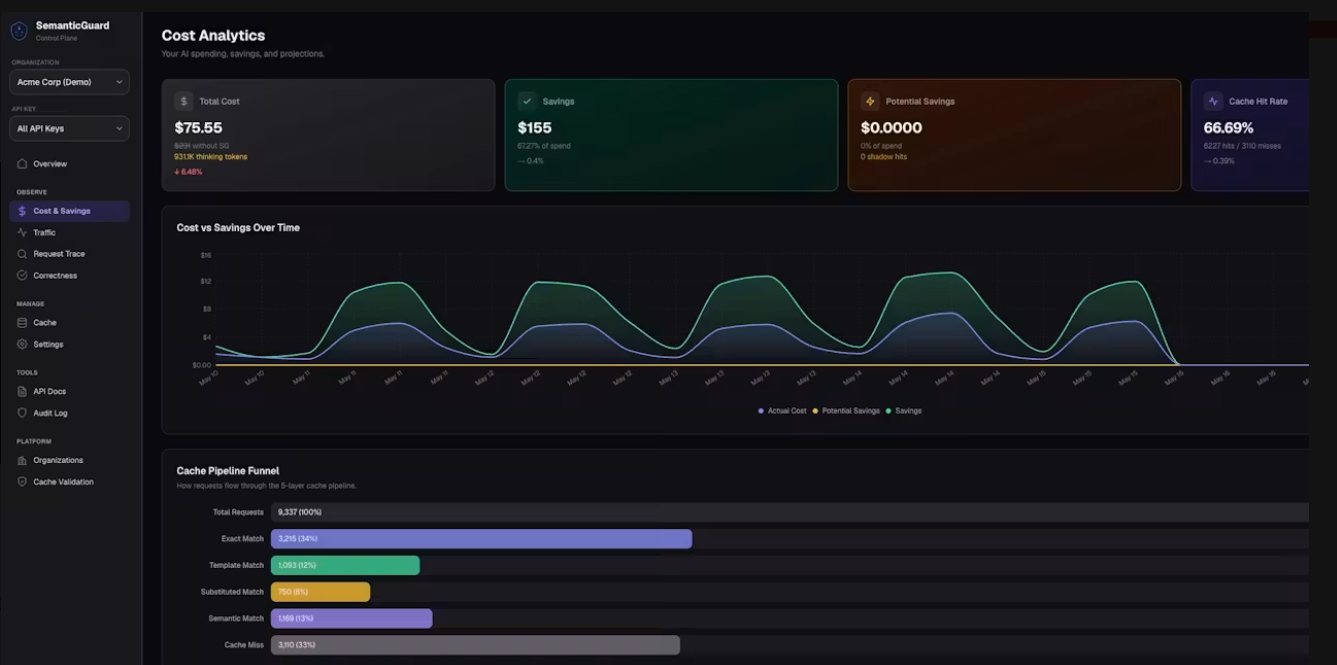
Hunter's comment
Most LLM calls in production are repeats. Same questions, same prompts, sometimes worded slightly differently. SemanticGuard caches them. Sits between your app and OpenAI/Anthropic/Google, returns cache hits in <50ms, cuts costs 40-70%. One line of code to install. Shadow Mode shows your savings before you flip caching on. Every hit validated by your own AI so you never serve a wrong answer.
Link
https://www.semanticguard.dev/

This is posted on Steemhunt - A place where you can dig products and earn STEEM.
View on Steemhunt.com
Congratulations!
We have upvoted your post for your contribution within our community.
Thanks again and look forward to seeing your next hunt!
Want to chat? Join us on: