📢 Optimization of Website Access Instability Issues
Recently, the website has been experiencing unstable access.
In the background, we can see that the AWS AutoScaling Group has been constantly starting new machines and shutting down old ones.
This should be the apparent cause of the unstable user access.
A user's current access might be on this machine. But the next second, this machine could be shutdown by the AWS AutoScaling Group. That cause the unstable access.
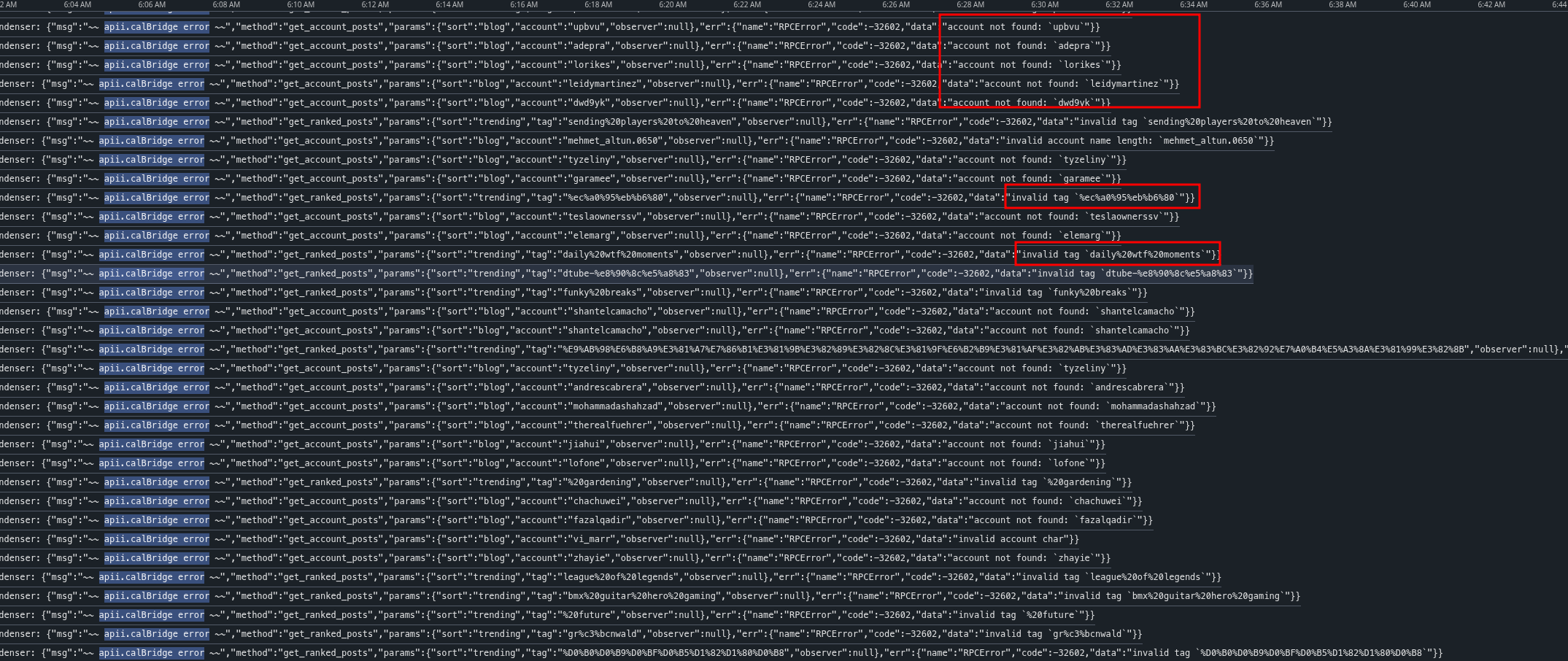
I spent a long time troubleshooting and finally found that the possible reason is that the exception handling of callBridge() is imperfect.
As a result, the exception is finally thrown at the top level, and eventually a 500 error occurs.
The ELB health check wrongly takes this as a signal, deems the node in AutoScaling Group to be in an unhealthy state, and then shuts down the machine and starts a new one.
We can also see this situation on this charts below.
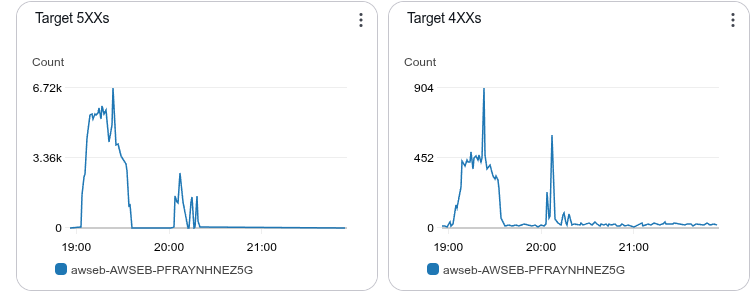
The 500 errors lead to frequent machine replacements, which in turn cause more 500 errors to occur.
The situation won't recover until no more traffic enters.
Now I have optimize the callBrige() method.
https://github.com/steemit/condenser/pull/3964.
This issue is also on the wallet site.
https://github.com/steemit/wallet/pull/270
These two PR have been online.
At the same time, in the ELB health check, I added a configuration to make the health check ignore 404 errors from the backend service.
Let us watch a period time to make sure the issue is fixed.
Upvoted! Thank you for supporting witness @jswit.