*TrufflePig*: Introducing the Artificial Intelligence for Content Curation and Minnow Support
Being a minnow on Steemit can be tough, your well-crafted posts may get unnoticed and buried in the noise. Accordingly, I made a proposition to develop a new Artificial Intelligence (AI), codename TrufflePig, to help the Steemit curation community by identifying overlooked and undervalued content. The best part of this proposition? I already have some data to show! I already experimented a bit and developed a prototype. Here I want to briefly discuss and summarize my initial results. So feel free to upvote, resteem, and comment on this post to support the further development of the bot.
The general idea of this Artificial Intelligence is the following:
We train a Machine Learning regressor (MLR) using Steemit posts as inputs and the corresponding Steem Dollar (SBD) rewards as outputs.
Accordingly, the MLR should learn to predict potential payouts for new, beforehand unseen Steemit posts.
Next, we can compare the predicted payout with the actual payouts of the Steemit posts. If the Machine Learning model predicts a huge reward, but the post was merely paid at all, we classify this contribution as an overlooked truffle or hidden gem.
As we will see later in the examples, this works surprisingly well for a first prototype!
In an online and live version of the bot we would publish hidden gems within the 7 days payout period (maybe posts between 2 and 6 days old) such that the community still has some time to give the truffles a proper reward.

Image from goodfreephotos
Data Scraping and Pre-Processing
I used the official steem Python library to download about 38,000 quite recent posts from the Steemit blockchain. Next, I performed some pre-processing and filtering. For example, I filtered images and links using regular expressions like this one:
def filter_images_and_links(text):
return re.sub('!?\[[-a-zA-Z0-9?@: %._\+~#=/()]*\]\([-a-zA-Z0-9?@:%._\+~#=/()]+\)', '', text)
Next, I only kept posts with at least 1000 characters left. Our AI should learn to identify high quality written content. Meme and video posts that go viral are not considered and ignored by the filtering. Moreover, I am only interested in contributions written in English. To filter for English only posts, I used the language detect library.
Feature Engineering
Usually the most difficult and involved part of engineering a Machine Learning application is the proper design of features. How are we going to represent the Steemit posts so they can be understood by an Artificial Intelligence?
It is important that we use features that represent the content and quality of the post. We do not want to use author specific features such as the number of followers or past author payouts. Although I am quite certain (and I'll test this sometime soon) that these are incredibly predictive features of future payouts, these do not help us to identify overlooked and buried truffles.
I used some features that encode the style of the posts, such as number of paragraphs, average words per sentence, or spelling mistakes. Clearly, posts with many spelling errors are usually not high-quality content and are, to my mind, a pain to read. Orthography checks were performed using PyEnchant.
Still, the question remains, how are we going to encode the content of the post? How to represent the topic someone chose and the story an author told? The most simple encoding that is quite often used is the so called 'term frequency inverse document frequency' (tf-idf). This technique basically encodes each document, so in our case Steemit posts, by the particular words that are present and weighs them by their (heuristically) normalized frequency of occurrence. However, this encoding produces vectors of enormous length with one entry for each unique word in all documents. Hence, most entries in these vectors are zeroes anyway because each document contains only a small subset of all potential words. For instance, if there are 150,000 different unique words in all our Steemit posts, each post will be represented by a vector of length 150,000 with almost all entries set to zero. Even if we filter and ignore very common words such as the or a we could easily end up with vectors having 30,000 or more dimensions.
Such high dimensional input is usually not very useful for Machine Learning. We rather want a much lower dimensionality than the number of training documents to effectively cover our data space. Accordingly, we need to reduce the dimensionality of our Steemit post representation. A widely used method is Latent Semantic Analysis (LSA), often also called Latent Semantic Indexing (LSI). Thanks to the gensim project there exists a Python version of this algorithm. LSI compression of the feature space is achieved by applying a Singular Value Decomposition (SVD) on top of the previously described word frequency encoding. A nice side effect of LSI is that the compressed features can be interpreted as topics and we can identify which words are most important (contributing positively or negatively) to form such a topic.
For example, in our (training) dataset the first identified topic by the gensim LSI is best represented by the words post, latest, sp (I presume short for steem power) and flag. Most likely this topic is about curating and voting of Steemit posts. We all know that talking about Steemit itself is a quite popular topic among Steemians. Another topic is represented by the words bitcoin, yang and cryptocurrency. Makes sense, doesn't it? The first 15 found topics are given in the image below.

In summary, the final Steemit post representation consist of the LSI topic dimensionality reduction (I chose an arbitrary number of 100 dimensions) in combination with the previously mentioned style features, such as number of spelling errors.
Training of the Truffle Pig AI
Next, I randomly divided the data set into training (80%) and testing samples (20%). We use the training input vectors (topic reduction + style features) and the corresponding post payouts in SBD to train a Machine Learning regressor. I chose a Random Forest regressor from scikit learn because these are usually very robust to noise and do not require excessive tweaking of hyper parameters (in fact I did none!).
Our working hypothesis here is that the Steemit community can be trusted with their judgment. So whatever post was given a high payout is assumed to be high quality content -- and crap doesn't really make it to the top. Well, I know that there are some whale wars going on and there may be some exceptions to this rule, but we just treat those cases as noise in our dataset. Yet, we also assume that the Steemit community may miss some high quality posts from time to time. So there are potentially good posts out there that were not rewarded enough.
During training the Machine Learning model was able to pick up some rules and good mathematical representations of the training set as shown in the figure below and given by the model's performance score. The score is measured as 1-u/v, where u is the residual sum of squares (sum [(y_true - y_pred)^2]) and v is the total sum of squares (sum [(y_true - mean[y_true]))^2]). The score on the training set is quite high with 0.9. If we predicted perfectly, the score would be 1.0. By the way, to get a feeling for this value, a score of 0 would mean we are as good -or rather as bad- as the predictor that always assumes the average payout. Of course, the score could in theory become negative because we could be arbitrarily awful in predicting payouts; for example, predicting 1 Mio. SBD for each post would be pretty stupid.
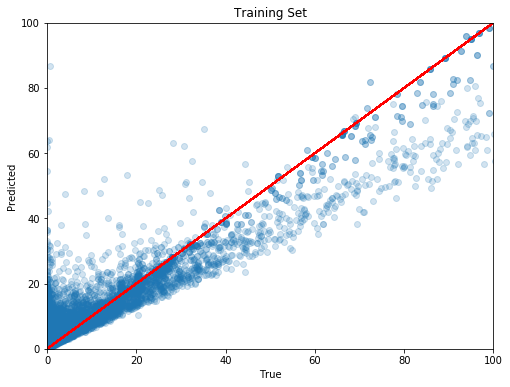
Moreover, you can look at the true reward in SDB (x-axis) versus the predicted one (y-axis) in the figure above. The identity line is shown in red. As you can see, the training predictions cluster nicely around this line. However, we do find some support for our working hypothesis: High rewards mean good posts in general, but writing a good posts does not automatically yield a high reward because the Steemit curation crowd might have missed it. How so? First, as shown in the figure for higher true rewards, the model usually underestimates the payout in SBD, and, secondly, the regressor predicted some high rewards for posts that almost did not get any reward at all.
Let us now use our trained truffle pig on the previously unknown test data. As expected, the performance is worse than for the training set, but still quite ok with a score value of 0.23. The data cloud no longer clusters so nicely along the identity line as for the training set, look at the figure below. Yet, in our model's defense, these are new posts that it did not see before and all Steemians know curation is hard!
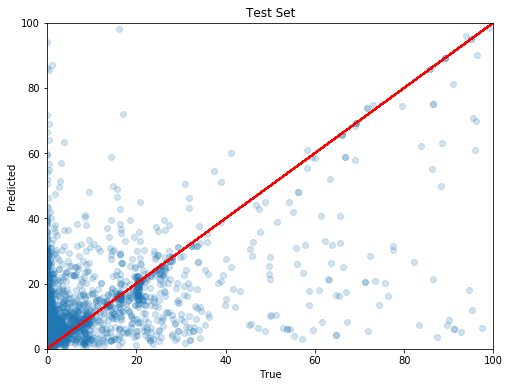
Do we find some hidden Truffles?
Let us come to the pressing question at hand: Did we find some hidden gems in the test set? Are there high quality posts that did not receive the reward they deserved? I would say, yes, for a first attempt the results are surprisingly convincing. Our Machine Learning pig did dig up some truffles. But, judge for yourself.
For example, among the top overlooked posts is the following one, which was given about 5 SDB, but our algorithm thought it is worth much more, that is 64 SBD. Surprisingly, its topic is very much related to the purpose of TrufflePig. It is titled "Re-Thinking Curation" and discusses the problems of the current curation system. The author makes suggestion on how to increase visibility of high quality content by changes to the voting structure:
"Ideally, only four numbers should matter when it comes to content curation (and none of those numbers are the SP of the person casting the vote). In fact, the four numbers that matter the most are right in front of us on every post:
How many times has a post been seen?
How many upvotes has it gained?
How many downvotes has it gained?
How many comments does it have?"
Other truffle examples are "What I found in the Last Jedi", that by the time of scraping was given less than 5 SBD, but according to the TrufflePig deserves about 58 SBD, or the short story series "The Shanghai Songbird" with about 8 SBD paid versus 40 Dollars predicted. Nevertheless, the pig did dig up some controversial matters such as this post with the title "In Defense of Aziz Ansari" (reward 1 SBD versus 87 predicted) or a very explicit story about a pornstar named Faye Reagan, I spare you the link here because it's very NSFW :-D
This concludes my short showcasing of the TrufflePig AI prototype. Still, there is a lot of room for improvement like better feature representations or trying out other Machine Learning methods. Moreover, I need to turn this offline model into an online bot that is regularly trained and regularly votes on and reports truffle posts. In fact, I already started the development in my Github repository. Hopefully, the TrufflePig will support the Steemit curation crowd soon and help to give proper rewards to quality content that deserves it.
In the meantime you can upvote, resteem, and comment on this and my proposition post! Please, do not let this one become an overlooked truffle... although I do like recursion, but I digress. So spread the word, and vote for some initial funding for the codebase and server setup! Of course, I will keep blogging about the bot's further development, so stay tuned for a detailed roadmap coming soon!
I am not a programmer, but the idea is quite impressive.
Do your best in coding.
We minnows badly need that in our post, since bots overlooked our post.
Is it an AI in a bot mode?
Well, the bot mode is still missing, I am currently working on that, though :-)
O wow
Intresting bro...
We r going to get many help
Thanks :-)
Hey bro can u upvote mine post
M new also so i doesn't get vote so i want help from all of u person
Although i am not a big fan of bots I think what you are trying to do is commendable.
Its a pity that something like this is even necessary to help find good content among all the nonsense but I really like your approach and think it could lead to a great curration trail.
this will surely help many. Keep it going
Well done!! Thanks a lot for taking such initiative. We the newly joined Steemians was facing such problems a lot.
Upvoted!!
@tech-mac
Looks like a cool project @smcaterpillar . Looking forward to read more about it!
May I give some thoughts which comes in my mind?
Have you removed common words like he, she, the, a ...? In your found topics it seems they are still in. Also html tags like "href" are in. Removing them could already improve your features.
Have you done a e.g. 5 fold cross validation of the training and test set? This often gives a more realistic view of the predicted results.
Did you have a look at the far outliers in the prediction and reviewed them manually? I think this could give interesting insights to improve your features.
Thanks for sharing :)
Hi, these are some good remarks, thank you. Let me address them one by one:
"Have you removed common words like he, she, the, a ...?" In your found topics it seems they are still in.
Yes, but rather arbitrarily. I just filtered any word that appears in more than one third of the training set posts. Apparently this has left
sheandhein there, but at least removedaandthe. I have to try to lower the threshold, maybe to 10 or 20% of all documents. Definitely worth trying to find a sweet spot via cross validation.Also html tags like "href" are in. Removing them could already improve your features.
Yes, damn, I wrote a bunch of regular expression filters, I missed
href, though. Will be included in the next version.Have you done a e.g. 5 fold cross validation of the training and test set? This often gives a more realistic view of the predicted results.
I haven't done any cross validation, yet. But will definitely do to tune some hyper-parameters such as number of topics or the word filter threshold. I have to see if it makes sense to also tune some forest parameters like
max_depth,max_leaf_nodes, or percentage of features at each split. What I have done though is to run the model a couple of times with a different RNG seed to see if results are consistent and robust (they are).Did you have a look at the far outliers in the prediction and reviewed them manually? I think this could give interesting insights to improve your features.
I haven't done a very thorough investigation, yet. However, the truffles you are seeing in the post above are, by definition, some outliers, they have the highest difference between real payout and predicted.
Thanks for the feedback, really appreciated!
Nicht schlecht nicht schlecht. Eine Sache die ich noch als Problem sehe ist dass die Post die da gefunden wurden eben schon ziemlich alt sind.
Danke und ja, das stimmt natürlich. Das ist der Offline Prototyp. Der Online Bot lebt wahrscheinlich in einem Dockercontainer auf einem Server und scraped Steemit in regelmäßigen Intervallen und macht dann auf Trüffel aufmerksam, die so zwischen 2 und 6 Tagen alt sind, sodass die Community noch Zeit hat Votes zu platzieren.
Wow. I am a software engineer and I find your work amazing. Just read it and I guess it was a monumental work. We await more data, I have worked a little with voice recognition and machine learning, for the software I work on and I know how painstaking it is. You deserve the boost you are getting from our common friend :)
Thanks, in fact, the monumental work is still ahead. I do a lot of Machine Learning, my daily bred and butter kinda thing, so setting up a Jupyter notebook to do the stuff above took me no more than a few hours. However, turning the Prototype into a production ready bot, this will be a lot more man hours of work.
trufflepigsteemit account is also a problem, I registered the account more than a week ago and haven't heard anything back, yet.I am all buckled up for the ride :)
The ride is pretty much ongoing and the bot live and deployed: @trufflepig
TrufflePig. Love it. Great combination of technical and writing acumen. Thanks for contributing such a valuable proposition to our community!
That looks very interesting. I hope your algorithm will exclude rewards given from bots, to determine a more accurate evaluation of the public's view of a post.