Spanish Translation of Node.js (Part 18) (1158 words)

Hello,
This is my 18th contribution to Node.js. I’m currently translating this project into Spanish, along with an awesome group of translators and moderators from Utopian + Da Vinci, we are doing our best to do everything correctly. If you are interested in open-source projects, I encourage you to keep reading.
Node.js is a very extensive project, it may seem impossible to translate it completely, but the Spanish team is working really and we are slowly making progress. We just hit 30% on Crowdin (yay!)

Repository
https://github.com/nodejs/i18n
Project Details
Node.js is an open-source, cross-platform JavaScript run-time environment that executes JavaScript code outside of a browser. It achieves low latency and high throughput by taking a “non-blocking” approach to serving requests. Basically, Node.js can open, create, read, write, close and delete files on a server, using JavaScript. It also includes tasks that will be executed on certain servers.

I know it can be a bit confusing at first, so let me explain it to you in simpler words:
Let’s say you want to build a software to keep record of your company’s earnings. A feature where viewing your monthly earnings is updated live can be very useful. In that way, if one of your sales employees is busy, another employee could still be seeing the updates live, without reloading the page.
This has been done before using another technologies. However, Node.js is way faster and better. So, yes it is the best option for developers who want to build real-time applications where both the server and the client can exchange data freely with no restrictions.
Contribution Specifications
Being such an important project, Node.js is being translated to several languages so it can reach many people around the world. As it for me, I am contributing to the Spanish language.
Translation Overview
This is my 6th contribution to the folder buffer.md on v6. The Spanish team started to translate Node’s files of the v10, now we’re progressively moving to the version 6 of this awesome project. Since I’m not a guru in computer science I had to read a lot before I could feel confident enough to translate the content of this folder, which is something you must regularly do while translating Node.js since it has many specific terms related to computer science.
buffer.md talks about the Buffer class and all of its functions inside Node.js. This time I translated the methods: buf.length, buf.readDoubleBE(offset[, noAssert]), buf.readFloatBE(offset[, noAssert]), buf.readInt8(offset[, noAssert]), buf.readInt16BE(offset[, noAssert]), buf.readInt32BE(offset[, noAssert]), buf.readIntBE(offset, byteLength[, noAssert]), buf.readUInt8(offset[, noAssert]), buf.readUInt16BE(offset[, noAssert]), and buf.slice([start[, end]]).
In my previous contribution I explained how streams are basically a sequence of data (normally bytes) being moved from one point to another over time. Binary data is the only type of data that can be executed by a computer and it’s represented in combinations of ones and zeros. And a Buffer is a portion of the memory that stores a stream that's then collected and stored in variables inside the same Buffer.
So the Buffer class is basically a “waiting area” for information! When Node.js receives data that’s not ready to be processed yet it will send it to the Buffer and store it there until it’s ready.
Like I’ve mentioned before, inside this folder there are all the Buffer methods with a brief explanation of how to use them, the values you have to use to active the method and an example of the code. Once you understand how they work it gets easier to translate the text.
Bellow, I will explain some of the methods I found interesting during this contribution:


The method buf.slice([start[,end]]) returns a new buffer object using parts of an existing buffer. Note that the returned buffer will represent the same memory as the original.
The parameter start specifies where to begin the extraction and the parameter end specifies where to finish it (by the default at the end of the buffer).
Here’s how I translated that paragraph:

This next one is very simple:

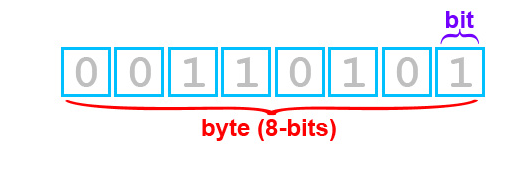
This method returns the amount of allocated memory of a buffer in bytes. Let’s remember that a byte is a unit of data that normally consists of a group of 8 bits. It is used by computers to represent characters, such as letters, typographic symbols or numbers.
On the other hand, a bit is the smallest unit of storage used by computers, it stores just one binary digit. So, it’s usually like this: 8 bits = 1 byte.
This short section could not be translated to Spanish because both sentences represent code values that belong to Node.js, therefore they would lose their true meaning and function if translated.
These next methods look kind of confusing but they are actually very interesting:

Their technical definition is that they return an unsigned 32-bit integer from a Buffer object at the specified offset with the specified endian format. readUInt32BE() returns big endian, while readUInt32LE() returns little endian.
What does this mean?
Alright, first I’ll explain what “endian” means. Endian refers to the way that data is sequentially stored in computer memory. So it’s basically the byte order chosen for all digital computing. Digital words can be represented either as big-endian or little-endian.
Data in big-endian is organized in a way that the most significant bytes or digits are shown in the upper left corner of a memory page, while the least significant ones are shown in the bottom right-hand corner.
Data in little-endian is organized in a way that the least significant bytes or digits appear in the upper left corner, while the most important bytes appear bottom-right. In case you didn’t notice, it’s just the opposite of “big-endian”.
These two concepts are mentioned several times throughout this contribution, that’s why I felt it was important to explain them.
Here’s how I translated the paragraph:

I used these sites as references: 1, 2, 3, 4, 5
Here are some other translation samples:
English:
Setting noAssert to true allows offset to be beyond the end of buf, but the resulting behavior is undefined.
Spanish:
Configurar noAssert a true permite que offset esté más allá del final de buf, pero el comportamiento resultante es indefinido.
English:
While the length property is not immutable, changing the value of length can result in undefined and inconsistent behavior.
Spanish:
Mientras que la propiedad length no es inmutable, cambiar el valor de length puede resultar en un comportamiento indefinido e incoherente.
Some words and code values were left untranslated on purpose, otherwise, their true meaning would be lost in the translation.
Languages
Source Language: English
Translated Language: Spanish
I have worked as a translator for the project Da Vinci Polyglot and I am currently working as a language moderator for the Utopian + Da Vinci translation category.
And of course, I am part of the Spanish team!
Word Count
I translated 1158 words on this contribution.
Proof of Authorship

Greetings, @marugy99. Thanks for submitting your contribution!
Congratulations on this contribution!
Gif source
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Chat with us on Discord
Thank you for your review, @alejohannes! Keep up the good work!
Hi @marugy99!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @marugy99!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!