시간 복잡도가 있는 선형 데이터 구조
데이터 구조란 무엇입니까?
[
](https://www.java67.com/2018/06/data-structure-and-algorithm-interview-questions-programmers.html)
데이터 구조는 데이터를 저장하고 구성하는 데 사용되는 저장소입니다. 효율적으로 액세스하고 업데이트할 수 있도록 컴퓨터에서 데이터를 배열하는 방법입니다.
데이터 구조는 모든 프로그래밍 언어의 빌딩 블록이며 모든 프로그래밍을 배우기 위한 토대를 마련합니다. 데이터를 저장하고 처리하고 검색하는 데 사용됩니다. 모든 소프트웨어 구성 요소는 서버, 데이터베이스, 대기열, 캐시, 로드 밸런서, 컴파일러 등 이름이 무엇이든 간에 데이터 구조에서 작동합니다.
데이터 구조는 두 가지 유형으로 분류됩니다.
- 선형 데이터 구조
- 비선형 데이터 구조
선형 및 비선형 데이터 구조란 무엇입니까?
선형 데이터 구조는 모든 요소가 순차적으로 배열되고 각 요소가 앞뒤 요소에 연결되는 간단한 구조입니다. 선형 구조를 사용하면 단일 실행으로 전체 항목을 탐색할 수 있습니다. 즉 구조의 처음부터 끝까지
선형 데이터 구조의 예로는 배열, 스택, 큐, 연결 목록 등이 있습니다.
선형 데이터 구조는 정적 및 동적 데이터 구조로 더 분류됩니다.
- 정적 데이터 구조: 정적 데이터 구조에는 고정된 메모리 크기가 있습니다. 미리 요소 수를 알고 있으면 정적 구조로 이동할 수 있습니다. 또한 정적 데이터 구조는 많은 검색 작업을 수행해야 하지만 자주 수정하지 않는 경우에 사용해야 합니다. 정적 데이터 구조의 요소에 액세스하는 것이 더 쉽습니다.
이 데이터 구조의 예는 배열입니다. - 동적 데이터 구조: 동적 데이터 구조에서는 크기가 고정되어 있지 않습니다. 항목을 추가하면 계속 커지고 항목을 제거하면 계속 줄어듭니다. 요소의 크기를 미리 알지 못하거나 많은 수정을 수행해야 하는 경우 동적 데이터 구조가 적합합니다.
이 데이터 구조의 예로는 Linked List, Queue, Stack 등이 있습니다.
비선형 데이터 구조: 비선형 데이터 구조는 데이터 요소가 순차적 또는 선형으로 배치되지 않는 구조입니다. 이러한 구조에서는 단일 실행으로 모든 요소를 순회할 수 없습니다. 단계별로 살펴봐야 합니다(예: 데이터를 탐색하기 위한 재귀적 접근 방식)
. 비선형 데이터 구조의 예는 트리와 그래프입니다.
이 기사의 초점은 배열 및 연결 목록에 있습니다. 깊이 잠수합시다.
배열
배열은 본질적으로 고정된 크기의 선형 데이터 구조 및 정적입니다. 인터뷰에서 묻는 기본적이고 가장 중요한 데이터 구조 중 하나입니다.
배열은 항목 목록을 순차적으로 저장하는 가장 간단한 데이터 구조입니다. 즉, 연속 메모리 위치입니다. Integer, String, Object 등과 같은 모든 데이터 유형을 저장할 수 있습니다.
배열에 대해 세 가지만 알면 됩니다.
- 배열 크기 — 선언할 고정 배열 크기입니다. 예: 7. 주어진 크기의 배열을 선언하면 시스템은 연속 메모리 블록 세트를 예약하여 사용자에게 제공합니다. 여기서 크기 7의 배열은 프로그래밍 방식 액세스를 위해 예약 및 제공됩니다.
- 배열 인덱스 — 배열 내 요소의 위치를 나타냅니다. 값을 삽입하고 검색하려면 색인이 필요합니다.
- 메모리 위치 — 배열의 모든 인덱스는 제공된 값을 메모리 위치에 저장합니다.


위 다이어그램에서 Integer 배열은 7개의 요소로 생성되므로 크기는 7입니다.
Java에서 Integer 값은 4바이트를 사용하며 값 0이 위치 100에 저장되면 값 1은 위치 104에 저장되고 값 2는 위치 108에 저장되는 식입니다.
어레이에서 수행되는 작업
배열에서 다음 세 가지 작업을 수행할 수 있습니다.
- 삽입 — 배열에 요소를 추가합니다.
- 삭제 — 배열에서 요소를 삭제합니다.
- Retrieve — 배열에서 요소를 검색합니다.
시간 복잡도
배열의 각 작업에 대한 시간 복잡도를 살펴보겠습니다.
- 조회/검색
Array에서 조회하는 것은 매우 쉽고 인덱스로 검색하기 때문에 O(1)입니다. 특정 인덱스에서 값을 가져와야 한다고 배열에 알립니다. 일정한 시간 O(1)에 가져올 수 있으며 Array의 크기가 크더라도 문제가 되지 않습니다.
2. 삽입
배열은 정적입니다. 즉, 배열의 크기는 고정되어 있으며 생성 시 결정해야 합니다. 우리는 얼마나 많은 항목을 미리 알아야 합니다. 배열 크기가 너무 크면 메모리를 낭비하는 것입니다. 배열 크기가 작으면 아래와 같이 배열 크기를 조정해야 합니다.
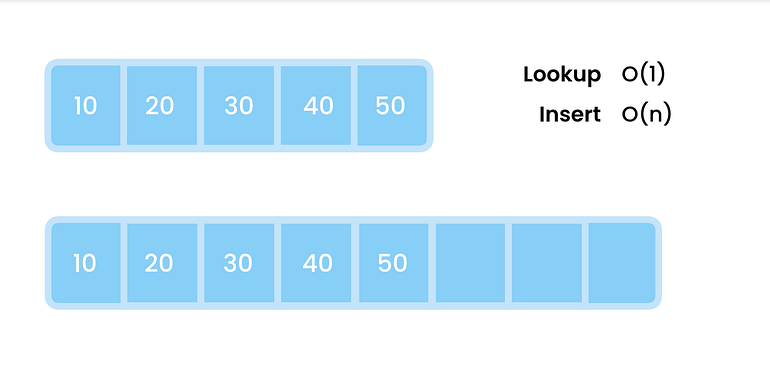
예: 위 다이어그램에서 배열은 처음에 4개의 요소로 생성되었습니다. 그런 다음 배열에 더 많은 항목을 추가해야 하는 경우 새 배열을 만들고 이전 배열의 모든 값을 새 배열로 복사한 다음 이전 배열을 삭제해야 합니다.
이 전체 작업에는 시간 복잡도가 필요합니다 — O(n)
따라서 Old Array에서 New Array로 요소를 복사하는 시간은 선형적으로 증가하며 크기 n이 크면 이 작업을 완료하는 데 오랜 시간이 걸립니다.
배열을 수동으로 생성하고 새 배열로 복사하는 작업을 피하기 위해 Java는 Collection 프레임워크에 있는 ArrayList라는 데이터 구조를 제공합니다.
배열 대 ArrayList


ArrayList는 내부적으로 배열을 사용하고 위에서 언급한 크기 조정 작업을 수행합니다. ArrayList의 크기 조정 작업은 새 배열을 포함하고 이전 배열에서 새 배열로 콘텐츠를 복사하므로 성능이 느려집니다.
배열은 프리미티브 또는 개체와 함께 작동할 수 있지만 ArrayList는 개체와만 작동하므로 배열과 비교할 때 동적으로 항목을 추가/제거하려고 할 때 유용합니다.
3. 항목 제거
배열에서 항목을 제거할 때 두 가지 가능성을 살펴봐야 합니다.
ㅏ. 최상의 경우
배열의 마지막 항목을 제거하는 것은 매우 간단합니다. 끝으로 이동하여 메모리를 지우기만 하면 됩니다. 일정한 시간이 걸립니다 O(1)
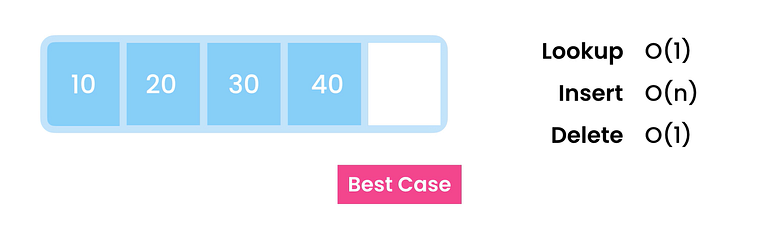
비. 최악의 경우
중간이나 처음에 항목을 제거하려면 최악의 시나리오를 고려해야 합니다. 여기서 첫 번째 항목을 삭제하고 모든 요소를 O(n)을 취하는 왼쪽으로 이동해야 합니다.
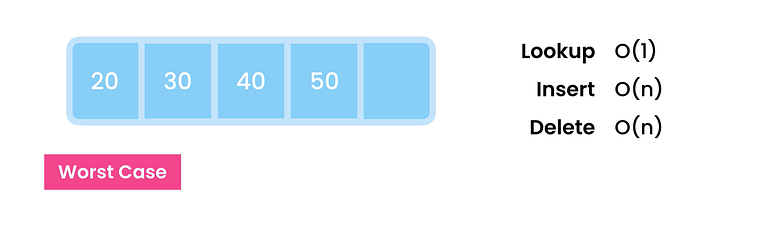
요약: 따라서 미리 배열의 크기를 알지 못하고 추가 또는 제거와 같이 데이터를 자주 수정해야 하는 경우 배열은 느리게 수행되는 경향이 있으며 적합하지 않습니다.
배열은 색인으로 조회하는 것이 매우 빠르므로 읽기 전용 데이터 세트에서 검색하는 데 가장 적합합니다.
LinkedList
연결된 목록은 선형 및 동적 데이터 구조입니다. 배열 다음으로 가장 일반적으로 사용되는 데이터 구조입니다.
연결된 목록은 배열의 단점을 해결하고 복잡한 구조를 구축하는 데 사용됩니다. 객체 목록을 순서대로 저장하고 요소를 추가/제거할 때 자동으로 확장/축소됩니다.
연결된 목록은 순차적으로 연결된 노드 그룹으로 구성되지만 Array와 같은 연속적인 메모리 위치는 아닙니다. 각 노드에는 데이터의 두 부분, 즉
- 값 — 노드에 저장할 값
- 주소 — 다음 노드의 메모리 위치
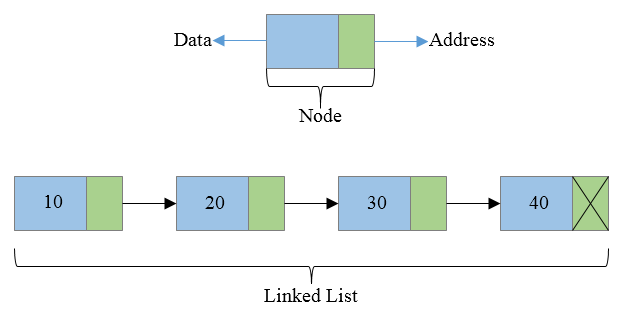
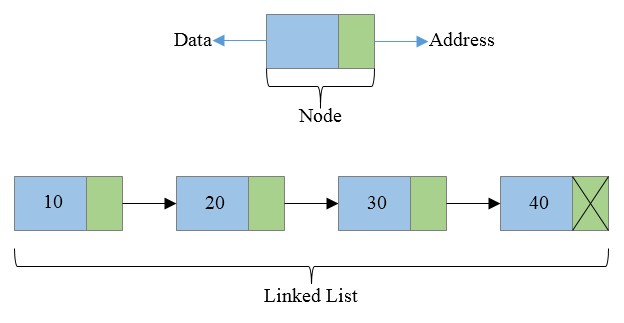
LinkedList에 항목을 추가하면 시스템은 2개의 섹션, 즉 데이터와 주소를 포함하는 해당 노드에 대한 메모리 블록을 예약합니다. 그런 다음 다음 항목을 추가하면 동일한 양의 공간이 예약되고 이전 요소는 두 번째 노드의 메모리 위치를 가리킵니다. 이것이 항목이 서로 연결되는 방식입니다.
전체 항목에 대해 메모리를 예약하는 배열과 달리 Linked List는 한 번에 하나의 항목(노드)에 대한 공간만 예약하므로 메모리 위치가 연속적이지 않습니다.
Linked List는 모든 노드가 다음 노드의 주소를 저장하기 때문에 배열보다 더 많은 메모리를 사용하며 이는 추가 오버헤드입니다.
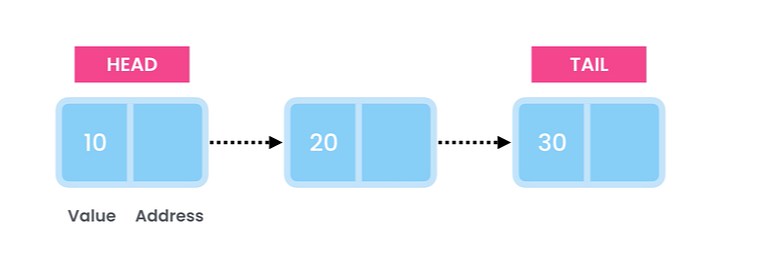
첫 번째 노드를 Head라고 하고 마지막 노드를 Tail이라고 합니다.
연결된 목록의 작업
Linked List에서 다음 3가지 작업을 수행할 수 있습니다.
- 삽입 — 배열에 요소를 추가합니다.
- 삭제 — 배열에서 요소를 삭제합니다.
- Retrieve — 배열에서 요소를 검색합니다.
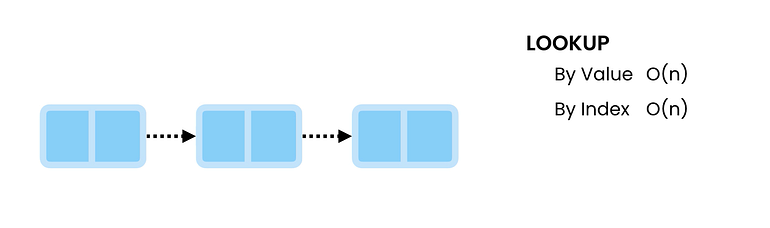
- 조회/검색
Array와 달리 LinkedList 노드는 연속된 메모리 위치에 저장되지 않을 수 있으므로 Array와 같은 인덱스를 통해 Linked List 조회를 수행할 수 없습니다. 따라서 연결된 목록은 실제 값을 찾을 때까지 헤드 노드에서 순회해야 합니다. 최악의 경우, 찾고 있는 항목이 Tail 노드에 있을 수 있으므로 O(n)입니다.
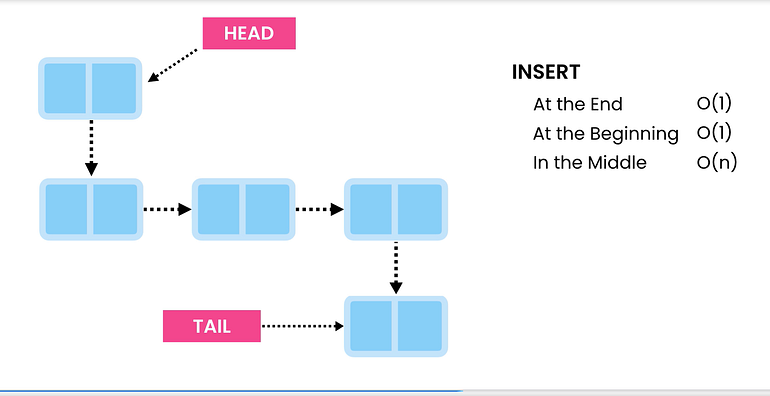
2. 삽입
항목을 삽입하는 위치에 따라 다릅니다.
시작 부분에 삽입하려면 새 노드를 만들고 헤드 노드를 가리키도록 합니다. 그런 다음 새 노드를 헤드로 만듭니다. O(1) 시간이 걸립니다.
마찬가지로 끝에 삽입하려면 새 노드를 만들고 Tail 노드에서 연결하면 됩니다. 그런 다음 새 노드를 꼬리 노드로 만들고 이것은 O(1) 복잡도에서 수행할 수 있습니다.
LinkedList에는 항상 헤드 및 테일 노드에 대한 참조가 있으므로 이를 찾는 것은 O(1) 작업입니다.
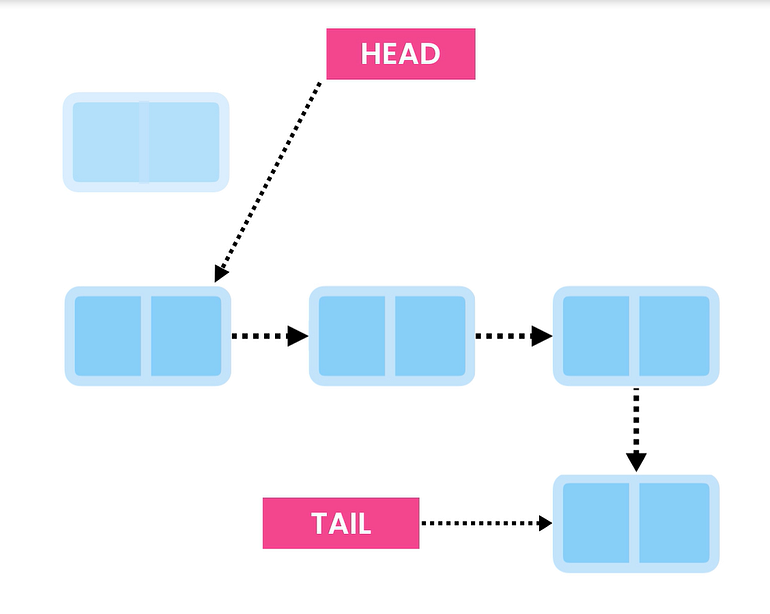
중간에 요소를 삽입하려면 O(n) 시간에 해당 노드로 이동한 다음 O(1) 시간으로 링크를 업데이트해야 합니다.
배열에서는 항상 항목을 왼쪽이나 오른쪽으로 이동하지만 LinkedList에서는 매우 간단합니다. 노드의 메모리 위치를 업데이트하기만 하면 됩니다.
3. 삭제
연결 목록의 3가지 삭제 시나리오를 살펴보겠습니다.
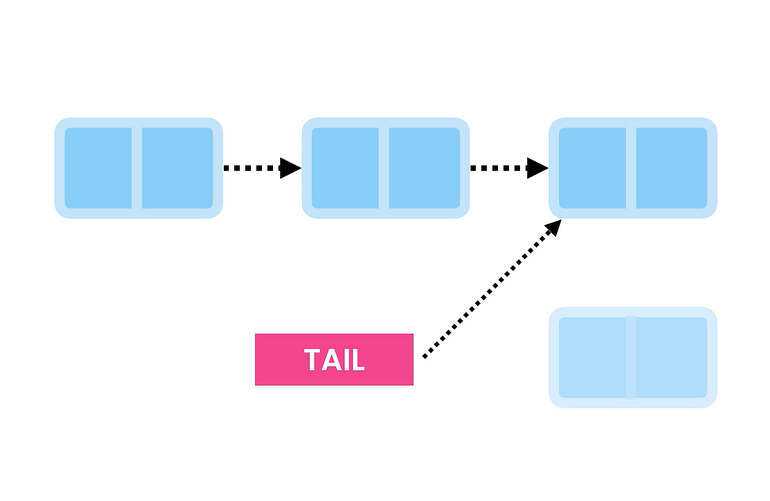
ㅏ. 처음부터 삭제 — O(1)
처음에 항목을 삭제하는 것은 매우 간단합니다. 헤드를 삭제하고 두 번째 항목을 O(1) 시간 내에 완료할 수 있는 헤드로 만들어야 합니다.
비. 마지막에 삭제 — O(n)
마지막에 항목을 삭제하려면 Tail 이전의 요소로 이동해야 합니다. 이것은 O(n) 시간이 필요합니다. Tail 노드 이전 노드에 도달한 후 Tail 노드를 삭제하고 이전 노드를 Tail로 만들어야 합니다.
씨. 중간에서 삭제 — O(n)
중간에서 항목을 삭제하는 것도 항목이 삭제되기 전에 노드로 이동해야 하기 때문에 O(n)이 걸립니다. 그런 다음 다음 항목을 가리키도록 링크를 업데이트하고 현재 항목을 삭제합니다. Java는 현재 노드에서 링크가 제거되면 이 노드에서 가비지 수집을 수행합니다.
LinkedList의 종류
Linked List에는 3가지 유형이 있습니다.
- 단일 연결 목록
- 이중 연결 목록
- 순환 연결 목록

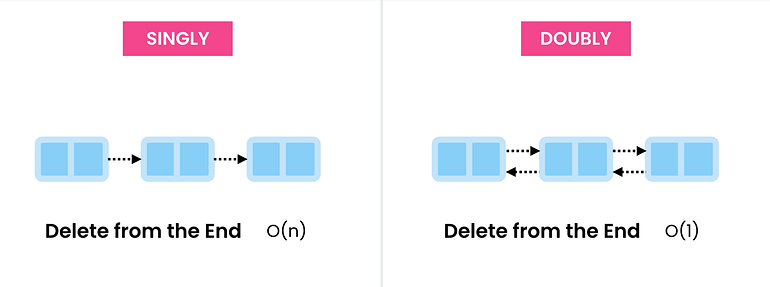
Singly Linked List에는 다음 항목의 주소에 대한 자리 표시자가 있지만 이중 및 순환 목록에는 이전 항목의 주소를 저장하기 위해 각 노드에 추가 주소 열이 있습니다.
이전 항목과 다음 항목의 주소가 있으면 목록의 양쪽에서 유연하게 이동할 수 있으며 특정 사용 사례에서 사용할 수 있습니다. 예: Circular Linked List를 사용하여 음악 재생 목록을 구현할 수 있습니다. 재생 목록의 끝에 도달하면 첫 번째 노래부터 재생을 시작할 수 있습니다.
추가 주소 필드는 목록에 추가 메모리 오버헤드를 추가하므로 이러한 데이터 구조는 시나리오가 필요한 경우에만 사용해야 합니다. 기본적으로 우리는 시간 효율성을 위해 메모리를 교환합니다.
배열 대 연결 목록 - 시간 복잡도 비교
배열과 연결 리스트의 시간복잡도를 비교해보자.
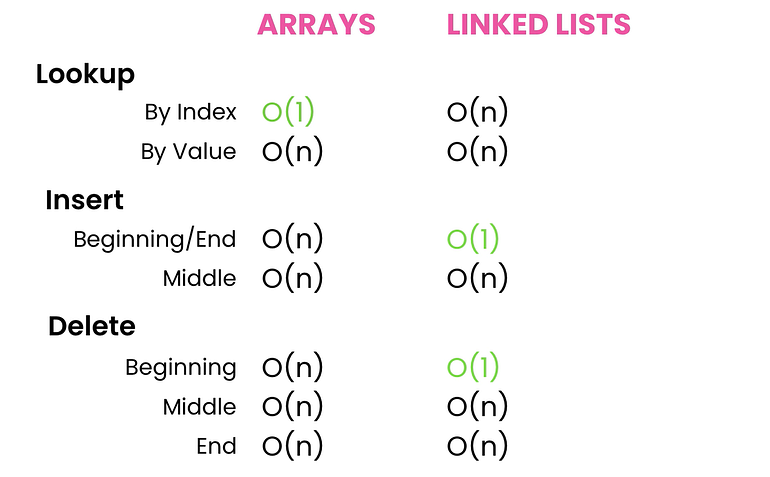
위의 그림에서 볼 수 있듯이 배열은 O(1) 시간의 조회에 사용되며 이러한 이유로 Stack, Queue, Hashtable 등과 같은 다른 데이터 구조에서 널리 사용됩니다.
반면 Linked Lists는 처음이나 끝에 항목을 자주 삽입할 때 사용됩니다. 또한 항목의 크기를 미리 알지 못하는 경우 연결 목록이 매우 좋은 선택입니다.
[광고] STEEM 개발자 커뮤니티에 참여 하시면, 다양한 혜택을 받을 수 있습니다.