AB 테스트 대신 인과적 ML 사용
복잡한 환경에서 Causal ML은 A/B 테스트보다 유연하고 강력한 가정이 필요하지 않기 때문에 강력한 도구입니다.
[저자 이미지]
반사실적 질문은 비즈니스에서 가장 중요한 주제 중 하나입니다. 나는 회사에서 항상 이런 종류의 질문을 하는 것을 듣습니다.
“우리는 이 조치를 취했습니다. 이후 평균 사용자 지출은 100$였습니다. 하지만 우리가 조치를 취하지 않았다면 그들이 얼마를 썼을지 어떻게 알 수 있습니까?”
이러한 문제는 일반적으로 A/B 테스트를 통해 해결됩니다. 그러나 A/B 테스트에는 여러 가지 요구 사항이 있으며 그 중 동시에 너무 많은 테스트를 실행하면 안 됩니다.
그러나 실제 조직은 서로 다른 프로세스가 지속적으로 진행되는 매우 지저분합니다. 따라서 테스트를 실행하는 동안 다른 모든 것이 일정하게 유지되고 있다고 가정하는 것은 종종 불가능합니다.
이것이 바로 이 기사에서 반사실적 질문, 즉 인과적 기계 학습을 해결할 수 있는 다른 도구를 살펴보는 이유입니다. Causal ML의 이점은 훨씬 더 유연하며 가장 중요한 것은 모든 비즈니스 프로세스를 거의 또는 전혀 제어할 수 없을 때 사용할 수 있다는 것입니다(데이터 과학자의 경우가 종종 있음).
문제 프레이밍
간단한 예를 들어보겠습니다. 사용자가 4명이라고 가정해 보겠습니다. 그들에게 할인을 제공하면 우리 플랫폼에서 더 많은 돈을 쓰게 될지 알고 싶습니다.
이것은 두 개의 평행 우주를 관찰 하라고 요구하는 것과 같습니다 .
하나의 유니버스에서 모든 사용자가 할인을 받습니다. 다른 우주에서는 어떤 사용자도 할인을 받지 못합니다. 두 유니버스는 사용자에게 할인을 제공하는(또는 제공하지 않는) 순간까지 정확히 동일합니다.
실제로 두 우주를 관찰할 수 있다고 상상해 보십시오. 다음 이미지에서 실험 결과를 볼 수 있습니다.
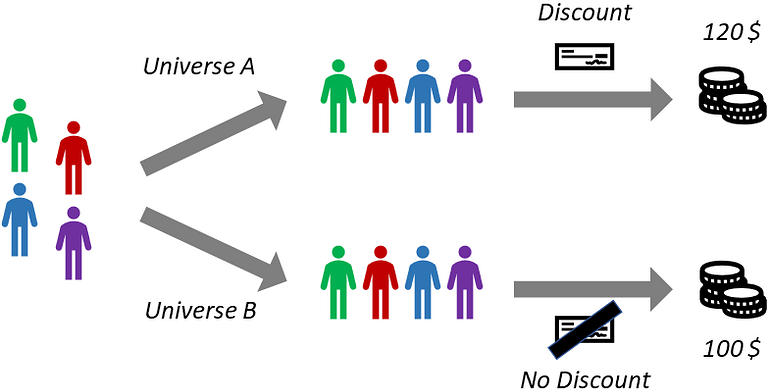
다중 우주에서 마케팅 활동 테스트: 하나의 우주에서 모든 사용자에게 할인이 제공됩니다. 다른 우주에서는 그들 중 누구도 할인을 받지 못합니다. [저자 이미지]
첫 번째 유니버스에서 사용자는 총 120$를 지출한 반면, 두 번째 유니버스에서는 총 100$를 지출했습니다. 따라서 우리는 할인이 사용자가 평균 5$ 더 지출하게 만드는 효과가 있다고 결론을 내릴 수 있습니다(120$ - 100$를 4명의 사용자로 나눈 값).
좋습니다. 할인이 적용됩니다!
평행 우주에서 A/B 테스트까지
불행하게도 실제로는 서로 다른 우주를 동시에 관찰할 수 있는 특권이 없습니다. 그래서 우리는 다른 방법을 찾아야 합니다. 이 방법은 A/B 테스트를 통해 제공됩니다.
A/B 테스트는 단일 유니버스에서 다른 유니버스를 생성하는 현명한 트릭입니다. A/B 테스트에서 우리는 사용자를 치료 그룹과 통제 그룹이라는 두 그룹으로 나눕니다. 그런 다음 치료 그룹에만 할인을 제공합니다.
두 그룹이 충분히 "유사"하고 두 그룹이 서로 영향을 미치지 않는다고 가정하면 이는 서로 다른 두 우주를 관찰하는 것과 매우 유사합니다.

A/B 테스트, 즉 단일 유니버스에서 마케팅 활동을 테스트합니다. [저자 이미지]
따라서 우리가 해야 할 일은 처리 그룹의 평균 사용자 지출(30$)과 통제 그룹의 평균 사용자 지출(25$)을 비교하여 할인이 사용자가 평균적으로 지출하게 만드는 효과가 있다는 결론을 내리는 것입니다. 5 $ 더 (30 $ - 25 $).
그렇다면 A/B 테스트의 문제점은 무엇입니까?
아무 것도 아닙니다. A/B 테스트는 잘 작동합니다.
하지만A/B 테스트의 요구 사항 중 하나는 서로의 결과를 "오염"시킬 수 있기 때문에 동시에 너무 많은 테스트를 실행하지 않는 것입니다..
실제 조직은 엄청나게 지저분하고 실제 프로세스는 A/B 테스트에서 요구하는 가정을 준수하지 않는 경우가 많습니다.
실제 회사에서 일어나는 일은 서로 다른 팀이 동일한 사용자에 대해 서로 다른 마케팅 조치를 취하는 것입니다. 그런 다음 귀하(데이터 과학자)에게 자신이 수행한 마케팅 조치의 효과를 평가하도록 요청합니다.
따라서 데이터를 분석하면 다음과 같은 사실을 알 수 있습니다.
- 일부 팀은 대조군을 별도로 두는 것을 잊었습니다.
- 일부 팀은 처리된 그룹과 충분히 유사하지 않은 대조군을 따로 보관했습니다.
- 일부 팀은 너무 작은 통제 그룹을 따로 보관했습니다.
- 서로 다른 팀이 충돌하는 마케팅 캠페인(예: 유지 캠페인 및 상향 판매 캠페인)을 동일한 사용자에게 보냈습니다.
- 일부 팀은 다른 팀의 컨트롤 그룹에 속한 사용자에게 마케팅 캠페인을 보냈습니다.
이렇게 지저분한 프로세스를 처리하면서 어떻게 견고한 통계 기반을 유지할 수 있습니까?
인과 ML 구조
인과 추론은 우리의 상황에 매우 잘 적응하는 프레임워크를 제공합니다.
사용자에 대한 정보 집합을 의미하는 공변량 집합이 있습니다. 마케팅 팀은 이러한 정보를 기반으로 결정을 내립니다. 이러한 결정은 마케팅 조치(치료라고도 함)의 형태를 취합니다. 예를 들어 지난 3개월 동안 구매하지 않은 사용자에게 할인을 보내기로 결정할 수 있습니다.
공변량과 처리의 조합은 우리가 관심 있는 KPI인 결과를 생성합니다. 이 경우 이것은 사용자의 지출일 수 있습니다.
다이어그램에서 이 프로세스를 요약해 보겠습니다.
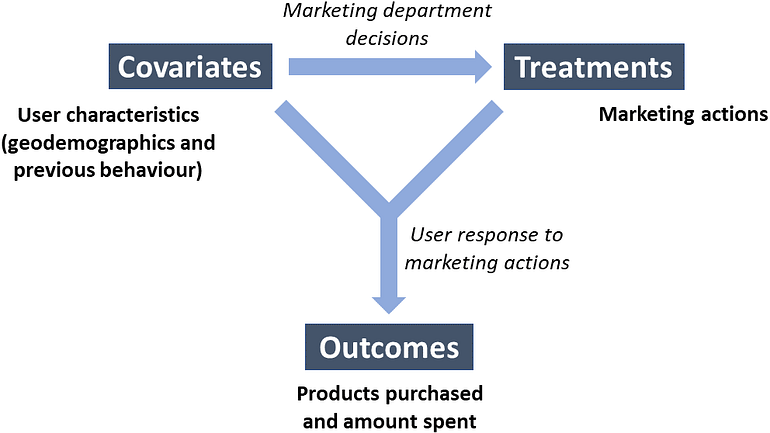
인과 관계 다이어그램. [저자 이미지]
좀 더 구체적으로 설명하기 위해 작은 데이터 세트를 상상해 봅시다. 데이터 세트는 각 원인 요소에 대해 하나씩 3개의 테이블로 구성됩니다. 공변량은 사용자 테이블에서 찾을 수 있습니다. 처리 또는 조치는 캠페인 표에서 찾을 수 있습니다. 결과는 구매 표에서 확인할 수 있습니다.

장난감 데이터 세트. [저자 이미지]
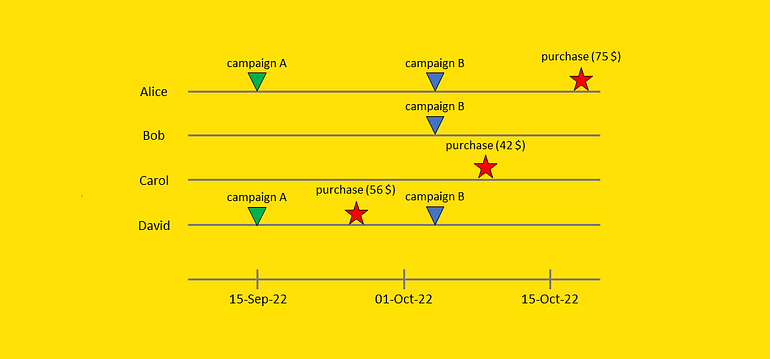
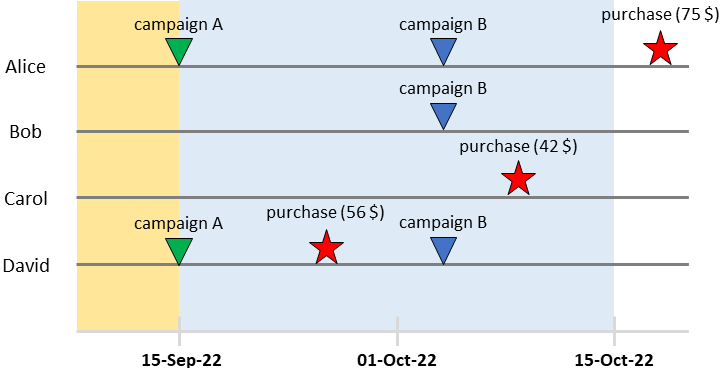
타임라인에서 각 사용자의 여정을 그래픽으로 시각화할 수 있습니다.
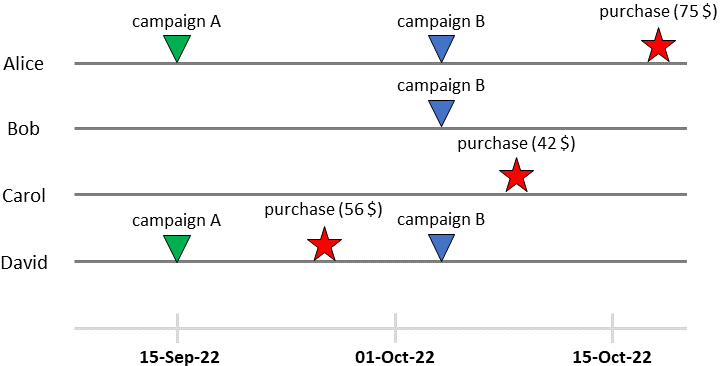
각 사용자의 고객 여정. [저자 이미지]
앨리스를 데려가자 그녀는 9월 15일 캠페인 A의 표적이 되었고 10월 4일 캠페인 B의 표적이 되었습니다. 그런 다음 그녀는 10월 18일에 구매했습니다(75달러 지출).
이제 해당 구매가 캠페인 A, 캠페인 B 또는 둘의 조합으로 인한 것인지 어떻게 알 수 있습니까? 하지만 무엇보다도 캠페인을 보내지 않았다면 그녀가 구매했을지 여부를 어떻게 알 수 있습니까?
이 문제를 해결하려면 기계 학습에서 자주 사용되는 단순화를 만들어야 합니다. 우리는 특정 시점(이를 컷오프 포인트라고 부름)을 선택하고 그 순간 이전에 일어난 모든 일(행동)이 그 순간 이후에 일어난 모든 일(결과)의 원인이 되었다고 가정해야 합니다.
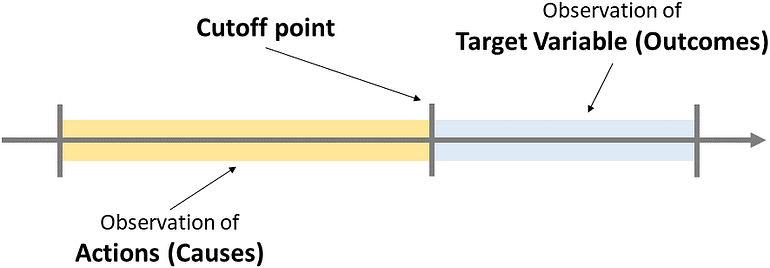
예측 모델의 시간 차원. [저자 이미지]
이제 우리는 이것에 동의했으므로 두 기간이 얼마나 길어야 하는지 결정하기만 하면 됩니다. 이는 비즈니스에 따라 크게 달라지며 조정할 수 있습니다(예: 이벤트가 마감 지점에서 얼마나 멀리 떨어져 있는지에 따라 이벤트에 가중치를 다르게 적용).
간단하게 하기 위해 작업 기간(이미지의 노란색 밴드)과 결과 기간(파란색 밴드)이 모두 한 달이어야 한다고 가정합니다.
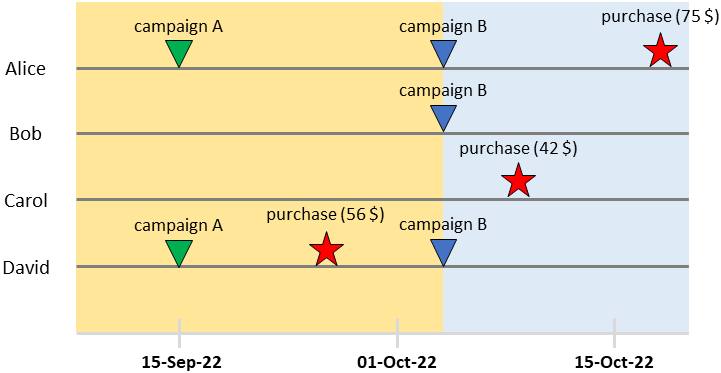
이 접근 방식을 사용하면 데이터로 돌아갈 수 있습니다. 캠페인 A가 9월 15일에 전송되었음을 알고 있습니다. 따라서 이 날을 모든 사용자의 컷오프 포인트로 삼을 수 있습니다.
노란색 배경: 행동 관찰. 파란색 배경: 결과 관찰. [저자 이미지]
결과(파란색 배경)를 관찰할 때 작업을 무시합니다. 이 경우 중요한 것은 결과입니다.
캠페인 B의 전송 날짜를 기준점으로 삼아 이 프로세스를 반복할 수 있습니다. 이 경우 다음을 갖게 됩니다.
노란색 배경: 행동 관찰. 파란색 배경: 결과 관찰. [저자 이미지]
공변량, 처리 및 결과를 종합하면 초기 데이터를 다음 형식으로 재정렬할 수 있습니다.
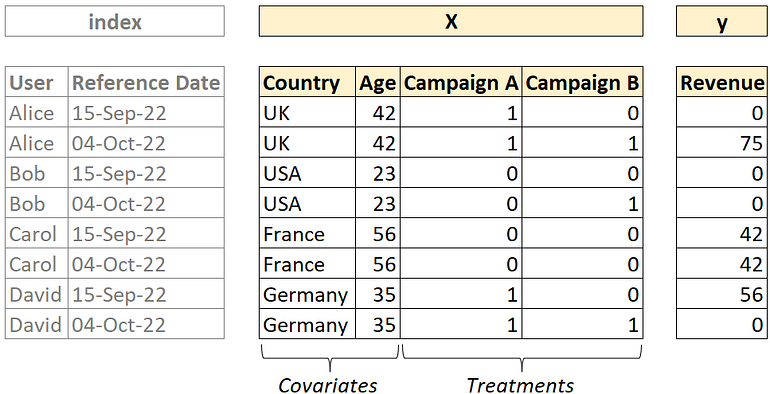
데이터 준비 후 데이터 세트. [저자 이미지]
이제 공변량과 처리로 구성된 독립 변수 세트(행렬 X )와 결과를 포함하는 하나의 목표 변수(벡터 y )가 있습니다.
이 두 가지 요소를 사용하여 이제 모든 기계 학습 모델을 교육할 수 있습니다.
모델 은 치료와 대상 변수 간의 관계(A/B 테스트에서 발생하는 것처럼)뿐만 아니라 치료와 공변량 간의 관계도 학습할 수 있습니다 . 예를 들어 프랑스 사용자는 캠페인 A에 더 반응하고 독일 사용자는 캠페인 B에 더 반응한다는 사실을 학습할 수 있습니다.
지금까지 우리는 이 문제를 전형적인 기계 학습 문제로 다루었지만, 이 경우 예측할 것이 없다고 반대할 수 있습니다. 그렇다면 애초에 ML을 사용한 이유는 무엇일까요?
직장에서의 인과적 ML
우리의 초기 목적은 다음과 같은 질문에 답하는 것이었습니다.
어떤 사용자에게도 캠페인을 보내지 않았다면 어떻게 되었을까요? 캠페인을 모든 사용자에게 보냈다면 어떻게 되었을까요?
Causal ML을 사용하면 반사실적 질문에 답할 수 있습니다. 또는 — 좀 더 거창한 용어로 표현하고 싶다면 Causal ML을 통해 다양한 우주를 시뮬레이션할 수 있습니다.
예를 들어 두 가지 시나리오를 시뮬레이션하고 싶다고 가정해 보겠습니다.
- 유니버스 A: 어떤 사용자에게도 캠페인을 보내지 않았다면 어떻게 되었을까요?
- 유니버스 B: 캠페인을 모든 사용자에게 보냈다면 어떻게 되었을까요?
이러한 시나리오를 시뮬레이션하는 것은 예측자 행렬에서 처리 변수의 값을 변경하는 것을 의미합니다. 매우 중요하기 때문에 이 점을 강조하고 싶습니다. 치료 변수만 변경할 수 있고 공변량은 변경할 수 없습니다 .
그래픽으로,
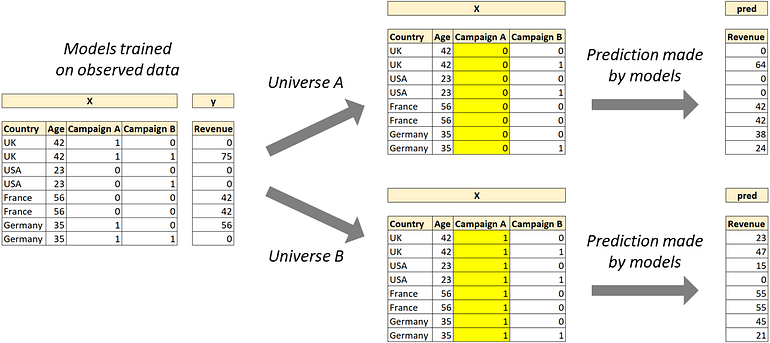
Causal ML을 사용한 다양한 시나리오의 시뮬레이션. [저자 이미지]
이 접근 방식이 얼마나 유연한지 아십니까? 우리가 관심을 가질 수 있는 모든 사용자 하위 집합에서 거의 모든 시나리오를 시뮬레이션할 수 있습니다.
이 시점에서 질문이 있을 수 있습니다. 모델을 교육한 동일한 데이터에 대해 어떻게 예측을 수행합니까? 기계 학습의 첫 번째 " 하지 마십시오 " 아닌가요 ?
교차 유효성 검사에서와 마찬가지로 데이터 세트를 여러 개로 분할하고 각 데이터 세트에 대해 다른 모델을 훈련하는 것으로 충분합니다.
import pandas as pd from sklearn.model_selection import KFold from lightgbm import LGBMRegressor = 5 folds = {fold: dict () for fold in range (n_folds)} for fold, (ix_train, ix_test) in enumerate (KFold(n_splits=n_folds).split(X=X)): folds[fold][ "ix_test" ] = ix_test 폴드[폴드]["모델" ] = LGBMRegressor().fit( X=X.loc[ix_train, :], y=y.loc[ix_train] )
이제 각 폴드에 대해 샘플 외부에서 훈련된 모델이 있습니다. 이 시점에서 이러한 모델을 사용하여 두 유니버스 각각에서 어떤 일이 발생할지 예측할 수 있습니다.
X_zeros = X.replace({ "campaign_A" : { 1 : 0 }}) X_ones = X.replace({ "campaign_A" : { 0 : 1 }} ) # 유니버스 B: 사람 이 . folds.keys() 에서 접기 : ix_test = folds[fold][ "ix_test" ] model = folds[fold][ "model" ] pred_zeros.loc[ix_test] = model.predict(X_zeros.loc[ix_test, :]) pred_ones.loc[ix_test] = model.predict(X_ones.loc[ix_test, :])
pred_ones"캠페인 A를 모든 사용자에게 보내고 다른 모든 것은 일정하게 유지했다면 어떻게 되었을까요?"라는 질문에 답합니다.
pred_zeros"캠페인 A를 어떤 사용자에게도 보내지 않고 다른 모든 것은 일정하게 유지했다면 어떻게 되었을까요?"라는 질문에 답합니다.
이제 우리는 캠페인 A pred_zeros와 pred_ones 관련하여 우리가 원하는 거의 모든 것을 계산할 수 있습니다 . 특정 하위 그룹의 평균 처리 효과, 중간 처리 효과 또는 우리가 관심을 가질 수 있는 다른 측정값입니다.
예를 들어 평균 처리 효과는 다음과 같이 계산할 수 있습니다.
먹었다 = (pred_ones - pred_zeros).mean()
위에서 본 동일한 논리가 이진 응답 변수에 적용될 수 있습니다(예: 사용자가 구매했습니까, 예 또는 아니오?). 이 경우 실제 확률을 예측할 수 있도록 모델을 보정해야 합니다.
합산
실제 조직은 복잡하고 다양한 프로세스가 지속적으로 사용자와 관련되어 있습니다. 이 상황에서 A/B 테스트가 의존하는 요구 사항이 반드시 충족되는 것은 아닙니다.
이 경우 Causal ML을 사용하여 반사실적 질문에 답할 수 있습니다. Causal ML에는 많은 장점이 있습니다. 유연하고 불가지론적이며 거의 모든 시나리오를 시뮬레이션할 수 있습니다.

출처 : https://towardsdatascience.com/using-causal-ml-instead-of-a-b-testing-eeb1067d7fc0
[광고] STEEM 개발자 커뮤니티에 참여 하시면, 다양한 혜택을 받을 수 있습니다.